What the Release of OpenAI’s gpt-oss-safeguard Models Means for Trust and Safety
As part of our close collaboration with OpenAI we were invited to evaluate, analyse and stress test the gpt-oss-safeguard models ahead of their release as a trust and safety specialist. In our work with clients to ship AI systems that are safe, fast, and dependable at scale, early access to the latest OpenAI deployments keeps our customers ahead. You can read more on the product launch here.
Over the past two years, we’ve built solutions that have safely scaled to millions of users. A key part of this work has been the design of fast, accurate moderation systems. Effective moderation enables companies to deploy cutting-edge AI solutions with confidence, protecting end users from harm and ensuring brand safety by catching unwanted generations before they become a problem.
Recently, OpenAI released their GPT-OSS-Safeguard models: fine-tuned versions of the 20B and 120B OSS models introduced earlier this year. These models can interpret a user’s policy directly at inference time, offering a flexible and powerful approach to content moderation. These models are in research preview, so will doubtless continue to improve over time.
Tomoro was proud to collaborate with OpenAI ahead of this release, conducting real-world evaluations to inform model development. In this article, we share insights from that collaboration and explore what these advances mean for the future of moderation in production AI systems.
How Does Moderation Work In Production Today?
Today, moderation solutions typically take shape as layers of protection wrapped around the application. We use this pattern a lot across high-volume, public-facing deployments. For a deeper dive, you can check out our blog on this here.
- Classify inputs in parallel (don’t let bad prompts in): Small, topic-specific classifiers run concurrently to label each user message. We’ve found that classifiers with a narrow focus are measurably more reliable than a single catch-all. Carefully chosen few-shot examples in the prompt can help make the difference between “I keep getting killed by this boss” (game context, completely harmless) and a real-world harm signal.
- Route decisively:
- Safe → Generate normally
- Jailbreaks → Ignore or deflect with an on-brand refusal
- Safety or wellbeing risks → escalate to a human with rich context
- Classify outputs (don’t ship a bad answer): Every candidate response is re-screened before delivery. This protects against model drift, RAG data-poisoning, and subtle policy edge cases such as harmful content, PII exposure, or sensitive information leak. If flagged, we substitute the LLM generated answer by a safe, brand-aligned message or escalate it to a human, rather than ship something we’ll regret.
- Make it fast and affordable: Building prompts as reusable building blocks allows you to cache prompt fragments, classifier few-shot examples, and common dialogue prefixes. This approach allows reduce both the latency and cost of your guardrails.
- Treat safety as a product surfaceRefusals and warnings are written in-voice (e.g., playful for games, formal for finance). When the UX respects the user’s intent, acceptance of guardrails goes up and jailbreak attempts go down
- Monitor, red-team, and close the loopContinuous red-teaming and live safety dashboards help catch regressions before they hit users. We can teach the model of any novel attack patterns by providing additional few-shot examples and/or routing rules so the system gets harder to break over time without compromising application performance.
Challenges When Building A Moderation Solution Today
Building and maintaining effective guardrails is difficult.
In practice it requires careful collaboration between key business stakeholders and developers to create well-defined policy. Then, once a policy is defined, the system design and behaviour of the system must be built and tuned.
The advent of open safety reasoning models such as gpt-oss-safeguard have the potential to resolve some of the pain points in this process, providing a more ready-to-use and versatile foundation for content moderation.
The Promise of Specialised Safety Models
Gpt-oss-safeguard aims to address some of the challenges that are common in building today’s moderation systems. These small, specialised models are fine-tuned to reason over a target policy at inference time, looking for harmful or sensitive content such as jailbreaks, PII exposure, and other policy violations.
By incorporating reasoning into their classification process, they deliver more accurate and resilient moderation that is harder to bypass. As specialised safety variants to GPT-OSS 20B and 120B, they enable state-of-the-art safety performance while requiring minimal setup overhead through custom policy definitions.
What we tested
We evaluated gpt-oss-safeguard 20B and 120B across several production-shaped tasks: a real-time voice assistant, an in-game player-support bot, a proactive chat moderation system, and a multilingual toxicity sweep (Spanish, French, Italian, Portuguese, Russian, and Turkish).
What we found
- Latency-sensitive voice moderation: In our real-time voice tests (think: live classification inside a conversation where a response has to be analysed and triaged, like gameplay chat moderation), gpt-oss-safeguard-20B closed c.80% of the accuracy gap between GPT-OSS-20B and GPT-5-Mini (0.71 vs. 0.78, up from 0.45) while running at greatly reduced latency.
- Player support escalation: In player-support triage, gpt-oss-safeguard-20B closed c.90% of the gap from GPT-OSS-20b to GPT-5-Mini (0.66 vs 0.67, up from 0.57). It also delivered the best-in-set macro precision, 88% recall on benign content, and 87% precision on vulnerable user detection—useful if you want conservative, high-trust escalations without flooding human reviewers.
- Policy-dense chat moderation at scale: On our most demanding evaluation, which requires a moderation system to proactively flag in-game messages according to a dense policy document, gpt-oss-safeguard outperformed the OSS baseline by a clear margin, achieving a c.35% relative lift, and handling long policies effectively. This is a particularly sensitive use case demanding high recall and precision. Too low on recall and many harmful messages will be missed. And a low precision score would lead to many irrelevant messages being flagged to human moderators, diluting their attention away from the truly difficult cases.
- Multi-lingual performance: On a balanced toxicity dataset across six languages, gpt-oss-safeguard tracked well with GPT-5-Mini, typically within 3-5pp on accuracy, with gpt-oss-safeguard-120B edging ahead in Spanish. We observed slightly larger gaps in lower resource languages such as Turkish, but the overall pattern was solid cross-lingual performance, with consistent recall gains when stepping from 20B to 120B.
We also observed that the gpt-oss-safeguard models perform strongly on areas where LLMs are traditionally weaker for moderation, such as PII data, where mainstream models tend to have more of a bias towards identifying US-style PII data, having weaker performance on other geographies. With this, we believe gpt-oss-safeguard will be useful for simplifying moderation set ups by reducing reliance on bespoke tools for picking up small infringements on policies that broader LLMs cannot handle.
The Power of Targeted Fine-Tuning
So, our evaluations have established that ‘foundation moderation models’ such as gpt-oss-safeguard-20B and gpt-oss-safeguard-120B will get you far, fast. However, domain-specific fine-tunes still set the bar when systems demand the highest standards of safety and specificity.
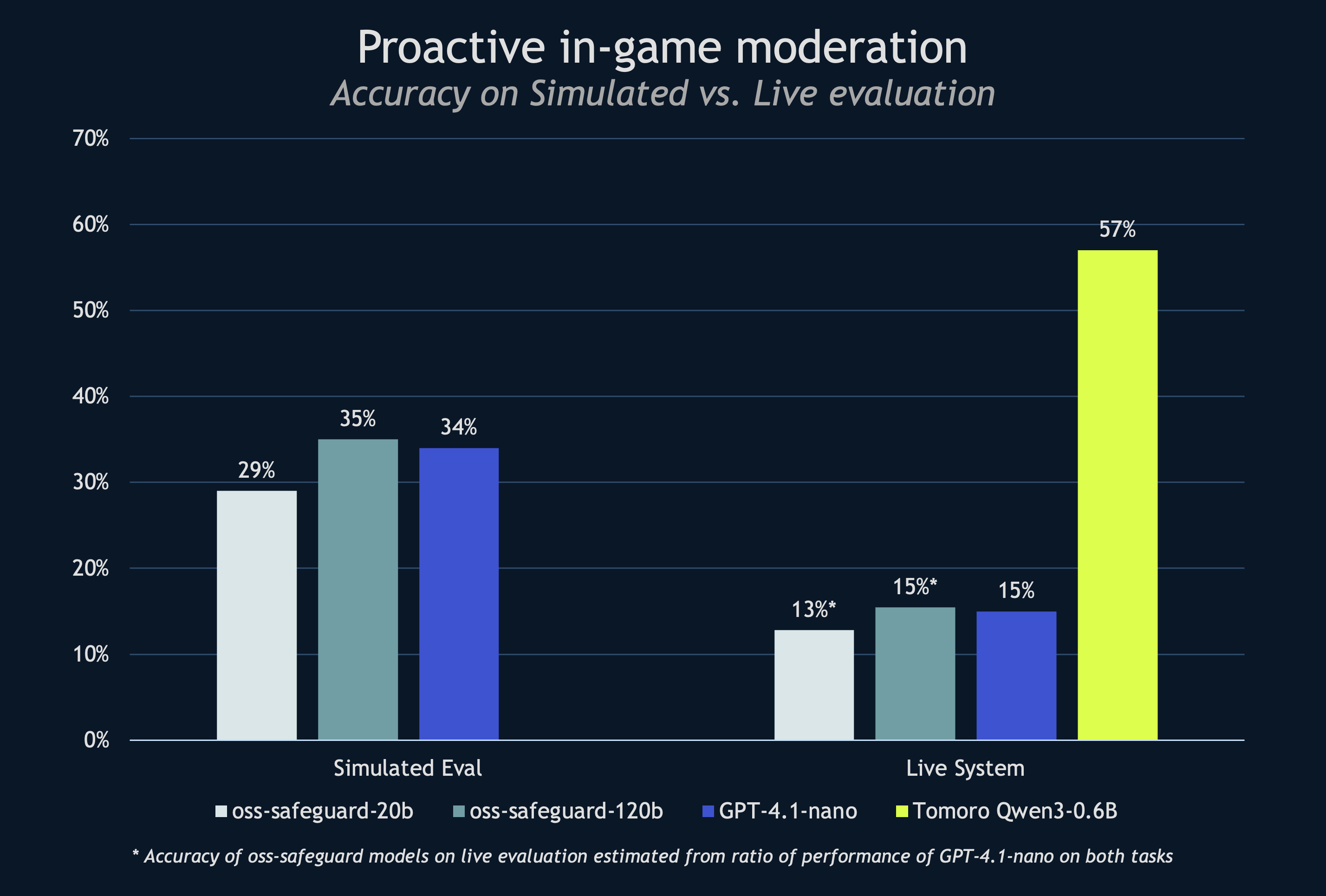
On the in-game moderation use case, we fine-tuned a Qwen3-0.6B classifier using supervised fine-tuning on c.10k historical moderator actions and policy outcomes. This model outperforms every base model we tested on this task by a substantial margin, achieving an accuracy of 57% vs. 15% (gpt-oss-safeguard-120B, estimated from ratio of GPT-4.1-nano performance), a +42pts, c.280% uplift. These results are consistent with OpenAI guidance that smaller, dedicated classifiers trained on labelled examples can outperform safeguard models for specialised domains.
The takeaway here is clear: when policies are nuanced and have lots of edge cases, a small, domain-tuned model remains the gold standard. The fine-tuning process bakes your policy and edge cases directly into the parameters, yielding steadier behaviour across the messy world of production, and doing so with tiny latency and cost footprints.
Supervised fine-tuning is only one of several possible approaches to this. One can also leverage other powerful training techniques such as reinforcement learning or on-policy distillation to further optimise model behaviour.
The Caveat With Fine-Tuning
Fine-tuning typically comes with a high data requirement. The dataset used for fine-tuning this Qwen3-0.6B classifier was a dataset that had been manually labelled by human moderators, and as such represented a clean, golden source of truth.
In many projects, this rich data advantage may not exist at the outset. Therefore we tend to think of fine-tuning as an optimisation that can come later in a solution’s development cycle. Once the shape of the solution has stabilised, and some real user data has been collected, developers can start to look to targeted fine-tuning to take their moderation solutions to the next level.
Closing Thoughts
Foundation moderation models like gpt-oss-safeguard are strong new building blocks. They have the potential to meaningfully simplify the design of moderation systems whilst cutting latency for real-time applications. Pair them with small, bespoke classifiers and you can build a system that safer and faster, with fewer moving parts than a prompt-based approach with large general models.
If you’re standing up or upgrading moderation today, consider starting with models like gpt-oss-safeguard first, measure the performance, and introduce targeted enhancements with bespoke classifiers (prompt-based or fine-tuned) where the data shows gaps.
Interested to learn more? Drop us a message.


