Meta-Harness R&D: Enterprise-Grade Self-Improvement for Long-Horizon AI Workflows
How autonomous code improvement can be made disciplined enough for enterprise use
Executive Summary
- Existing autonomous-improvement systems have shown strong results on coding tasks, but it remains unclear whether they can improve complex, long-horizon AI workflows that resemble real enterprise deployments.
- Our Meta-Harness Research applies autonomous self-improvement to agentic retrieval, deep research, and signal intelligence workflows while adding enterprise requirements such as held-out evaluation, auditability, budget controls, and human approval.
- Across three representative workloads, Meta-Harness substantially improved performance, including an 84% improvement on held-out test performance for Signal Engine and higher accuracy with 16× faster execution for Agentic Multimodal Retrieval.
- Unlike most prior approaches, Meta-Harness measures success on held-out datasets wherever possible to evaluate whether improvements generalise beyond the data used during optimisation.
- These results suggest that autonomous workflow improvement can extend beyond coding benchmarks to real-world enterprise AI systems, providing a practical path toward continuously improving AI applications.
Recent work on autonomous AI research, including the Meta-Harness paper, the CORAL framework, and karpathy/autoresearch, has shown that coding agents can iteratively improve a solution given an evaluation metric. What remains open is whether those methods translate to the long-horizon AI workflows, such as agentic multimodal retrieval, where an agent must iteratively search across multimodal domain corpora to answer a question, or complex data-processing pipelines that require many dependent steps, tool calls, and exception-handling decisions. The deeper question is whether the gains hold up on data the optimiser never sees.
Our Meta-Harness R&D is our answer to that question. It takes ideas from recent research and reshapes them around enterprise needs: held-out evaluation, audit trails, cost ceilings, and a clear hand-off point to a human reviewer before anything ships.
We tested it on three long-horizon tasks modelled on real client work. Signal Engine monitors a live stream of X posts about the AI market and produces well-sourced, structured trend reports. Agentic Multimodal Retrieval reasons over mixed text-and-image queries to return the most relevant document pages. Deep Research orchestrates multiple agents to search the web, cross-check sources, and write long-form research reports.
Results at a Glance
- Signal Engine: held-out test composite 0.456 → 0.841, an 84% relative lift. CORAL and karpathy/autoresearch stayed below 0.50 under the same budget.
- Agentic Multimodal Retrieval: held-out NDCG@10 0.705 → 0.744, with per-evaluation wall-clock time falling from 869s to 54s. That is a 16× speed-up at higher accuracy.
- Deep Research: report-quality composite 0.449 → 0.802 across 10 reference questions, against roughly 0.52 for the baselines. This task had no held-out split, so we treat the number as in-sample only.
- Search efficiency: with Predictive Hypothesis Reranking, Signal Engine reached 91% of the reference run's best score in 3 iterations instead of 20 on the same evaluation budget.
Most autonomous-research systems optimise and evaluate on the same dataset, which makes it impossible to tell whether the result generalises. For Signal Engine and Agentic Multimodal Retrieval we enforce a strict split: a training set candidates can score against, a development set for sanity checks, and a held-out test set the optimiser never sees. Every reported result comes from one specific code version scored on every split, so we never mix the best training score from one candidate with the best test score from another.
How it Works
Each round, the harness generates a batch of structured hypotheses for changing the code. Every hypothesis names the mechanism it wants to change, the prior version it builds on, and the failure mode it targets. A ranking step filters the batch before any expensive evaluations are spent. The surviving hypotheses go to parallel worker agents that share a common knowledge base but edit code inside fully isolated workspaces, so each candidate is graded fairly and independently. At the end of the round, the runner promotes one winner: the highest-scoring candidate that also passed every check on the visible splits. That winner becomes the frontier the next round builds onEvery trial writes a fixed bundle into an append-only evidence store: its code patch, per-split scores, an event log, and four short LLM-written analyses covering its trace, errors, cost, and a reflection. The next round's proposer reads this history back, which is how the harness compounds what it has learned instead of re-running the same dead ends.
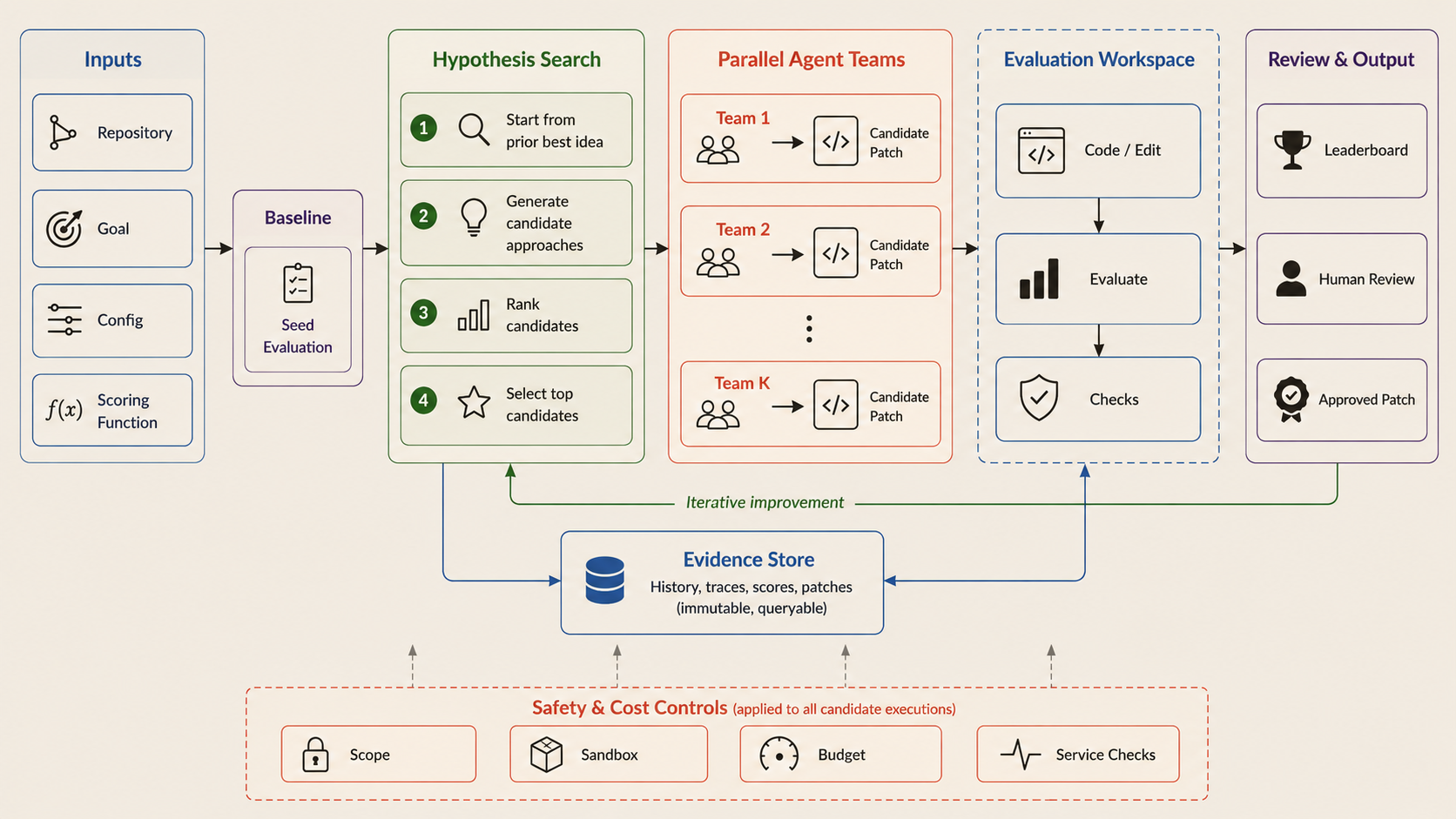
Three guardrails keep the loop safe to run. A scope policy restricts which files a candidate may touch and reverts anything outside it. Token and wall-clock budgets stop the run once spend crosses a ceiling, with concurrency limits keeping the harness inside model and GPU rate limits. And the harness never ships anything itself. It produces a ranked, fully documented candidate, and a human engineer reviews the diff and decides whether it goes to production.
Under the Hood
On a local stack, five engineering primitives sit underneath every round of the loop above.
- Workspace Isolation. A git worktree per candidate. Forks share an object database but never each other's files, which allows candidates to run in parallel at near-constant disk cost and makes it trivial to diff against the current frontier.
- Execution Sandbox. Dual-mode by config: native subprocess for fast iteration or a fully isolated runtime. Corpora mount read-only, and the per-trial scratch directory is discarded after grading. As a result, a trial cannot mutate the dataset or leak state into the next one.
- Scope Policy. A path allow-list declared in the experiment config. Anything touched outside it is reverted before the trial is graded, and the trial is flagged. Consequently, the diff a reviewer sees is guaranteed to remain within the declared scope.
- Budget Enforcement. Three layers: per-trial token and wall-clock caps, a per-run aggregate ceiling, and a concurrency limit. Together they keep spend predictable and ensure the harness stays within model and infrastructure rate limits.
- Evidence Store. An append-only JSONL of the code patch, per-split scores, event log, and the four LLM-written analyses. Materialised views (leaderboard, frontier, failure index) regenerate after each trial, allowing subsequent rounds to build on prior history while keeping every run reproducible byte-for-byte.
None of these primitives are optional. The point of the harness is to leave a reviewer with something they can actually approve at the end of a run: a winning candidate, a bounded diff, a full record of what was tried, and a known cost. Remove any of the five and one of those guarantees disappears.
Predictive Hypothesis Reranking
All three experiments use the same hypothesis strategy. Each iteration, the proposer generates more hypotheses than the budget can afford to run: M = 8 candidates for a dispatch budget of K = 4. A separate LLM ranker then orders all 8 in a single thirty-second call, with the full picture in front of it: the current best score and its weak dimensions, failure analyses from recent trials, and all 8 proposals side by side. The top 4 go to the executor at a cost of 15 to 30 minutes each. The other 4 are dropped before they spend anything.
Evaluations
The underlying models were held fixed throughout; the harness only edited the code around them. Signal Engine and Deep Research ran on gpt-5.5. Agentic Multimodal Retrieval ran on the open-weight Qwen3.6-35B-A3B served locally through vLLM, paired with a TomoroAI ColQwen3-4B image retriever, a combination chosen for predictable on-prem cost.
The chart below shows how the scores moved for our three main tasks. "Seed" is the starting code written by a human engineer. "Tomoro Meta-Harness" is the best version Tomoro Meta-Harness found. We see performance improvement for all three tasks in the held-out test set.
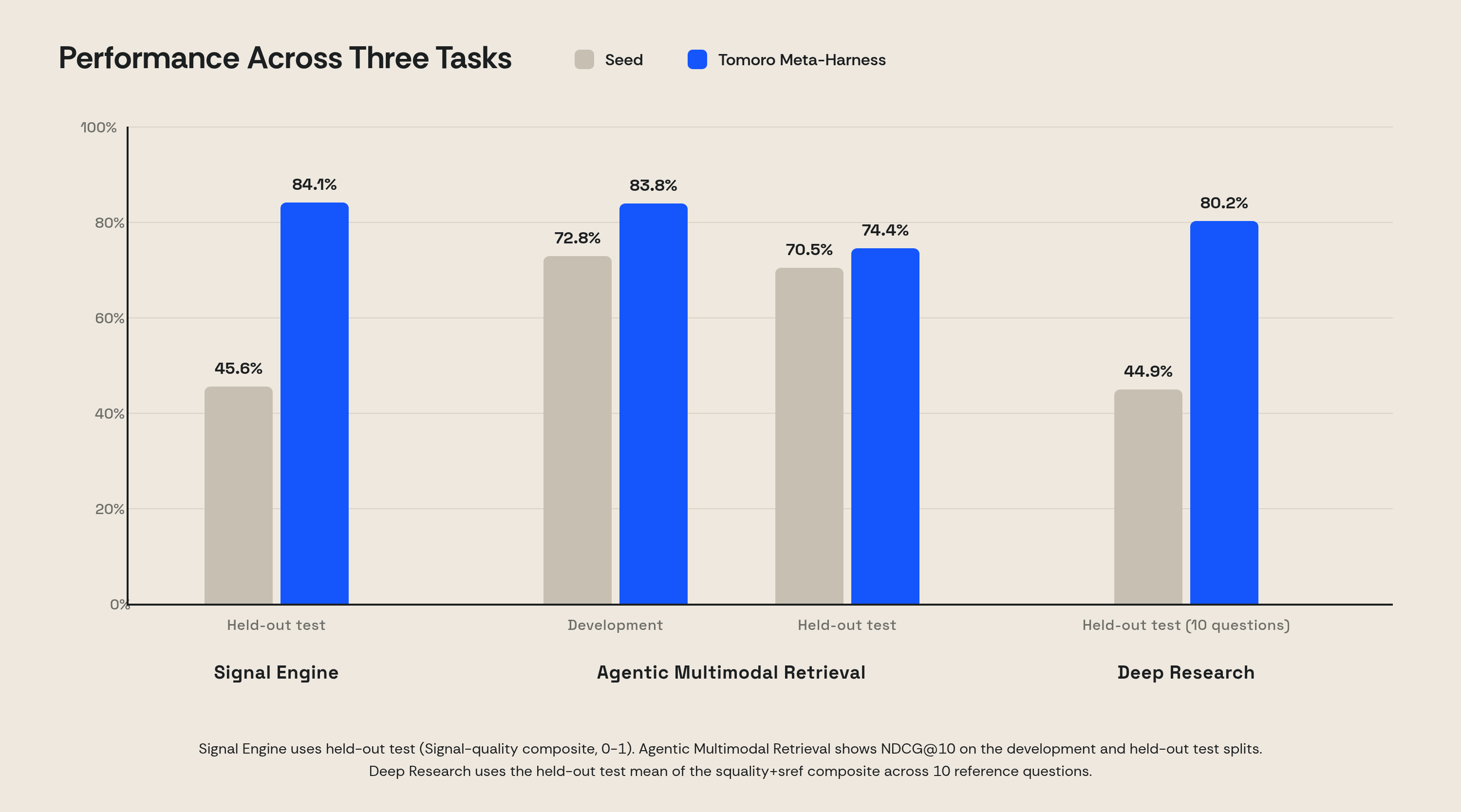
Signal Engine was evaluated by an LLM judge across freshness, factuality, granularity, and tone, using 150 training tweets and 150 held-out test tweets. Over the run, the best version improved the training composite from 0.431 to 0.756 and the held-out score from 0.456 to 0.841. The gains came from changes to the harness itself, not just prompt tweaks: winning iterations learned to filter social-media noise, added fact-cross-checking steps, and required every output to ground itself in explicit evidence. The diagram below shows the iteration process.
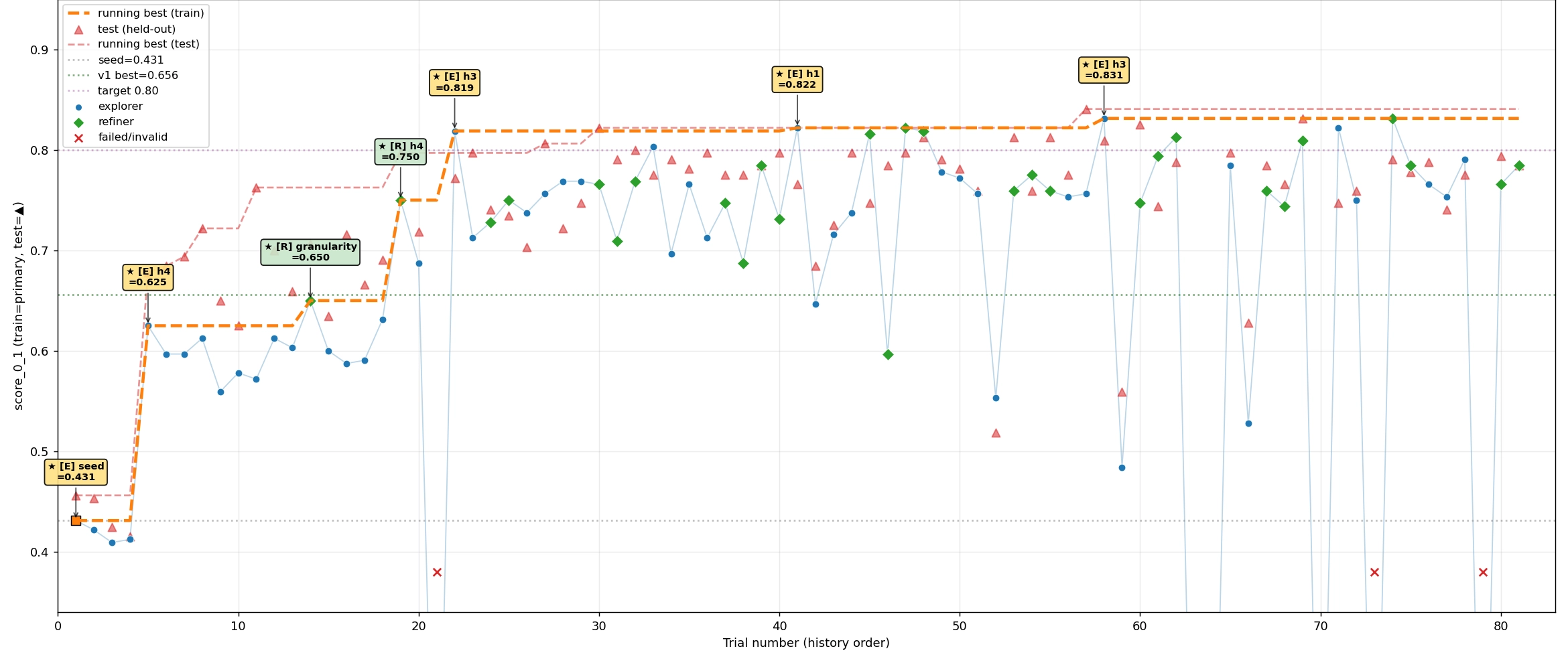
The trial history shows how those gains accumulated. An early structural change raised the running best to 0.625; finer-grained evidence handling pushed it to 0.679; and a refined reflection-and-rubric loop lifted it to 0.819. Roughly half of all candidate runs underperformed or failed outright, but they did not contaminate the leaderboard: each fork ran in isolation, losing diffs were discarded, and failures were written into the reflection store so the next proposer would not repeat the same dead end.
Most importantly, the held-out curve rose alongside the training curve throughout the run. That suggests the harness was improving the workflow rather than memorising the training corpus. The held-out scores were slightly above the training scores, which we interpret as ordinary sampling noise between two small, disjoint splits.
Agentic Multimodal Retrieval is measured with NDCG@10 on the public ViDoRe V3 Computer Science split, curated into 20 training, 10 development, and 20 held-out test queries. The harness raised held-out NDCG@10 from 0.705 to 0.744 while cutting total evaluation wall-clock from 869 seconds to 54 seconds.
Deep Research is graded on an LLM-judged composite of substantive quality and reference quality, following DeepResearch-Eval, across 10 reference questions. The improved code raised the mean from 0.449 to 0.802. The winning changes were easy to read off the diff: an upfront planning step that compares approaches before any research agents are dispatched, and a final review step targeting the dimensions where reports had historically scored poorly. Because this set is small and expensive to evaluate, we did not split it, and we treat the result as in-sample.
Comparison with CORAL and Karpathy/Autoresearch
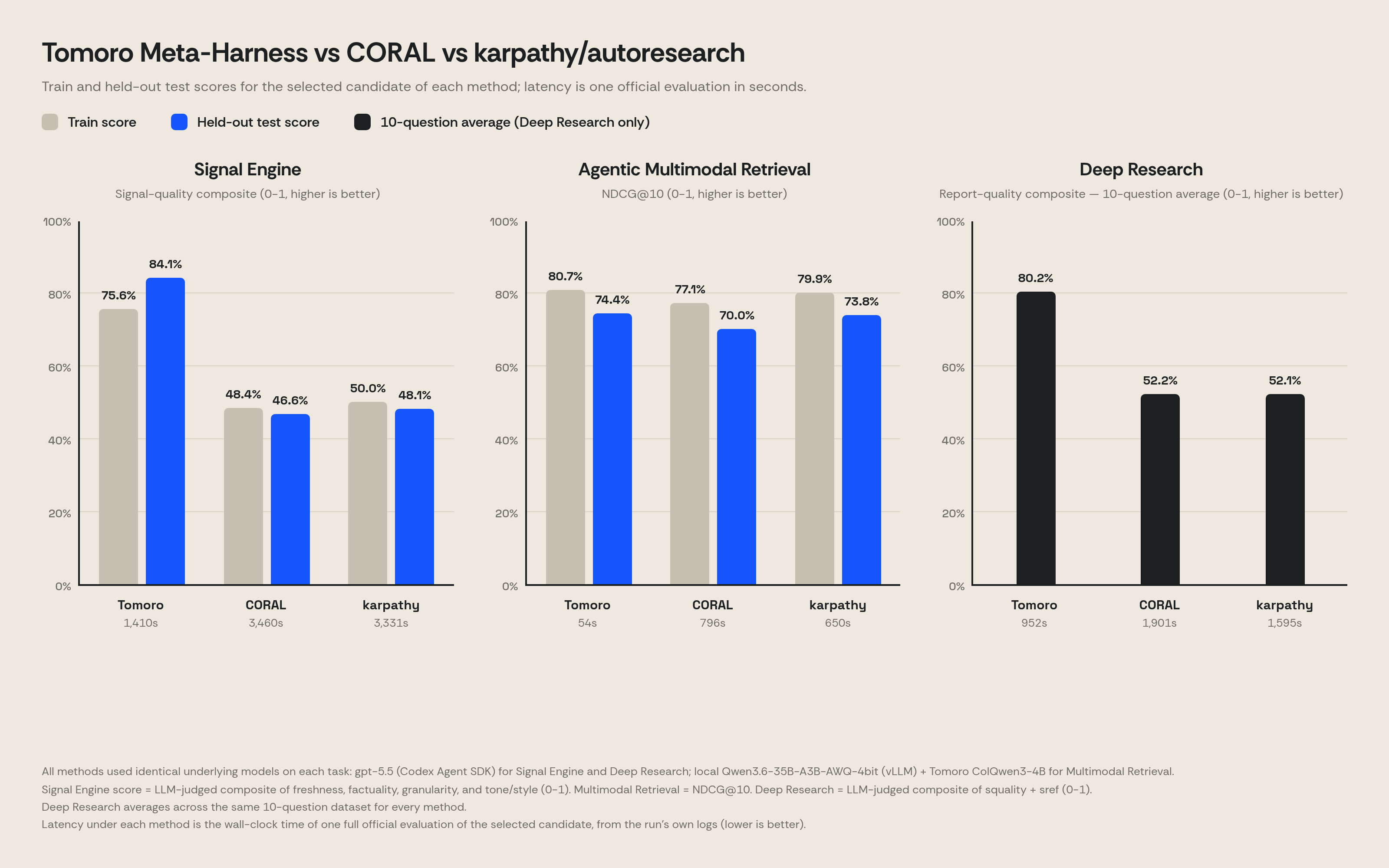
We benchmarked all three methods under the same budget: same datasets, same underlying models, same iteration cap, same total candidate evaluations. On Signal Engine, Tomoro Meta-Harness reaches 0.841 on held-out test while both baselines stayed below 0.50. On Agentic Multimodal Retrieval, Tomoro has the highest held-out NDCG@10 (0.744 against 0.700 for CORAL and 0.738 for karpathy) and runs the official evaluation twelve to fourteen times faster: 54s against 786s and 650s. On Deep Research, Tomoro reaches 0.802 while both baselines stayed near 0.52. One caveat applies throughout: we reimplemented CORAL and karpathy/autoresearch from their published descriptions, so some of the gap may reflect implementation differences rather than method differences alone.
Four design choices account for the gap. First, Tomoro generates a structured design spec before any code is edited, which biases it toward structural changes like new pipeline stages rather than prompt tweaks. Second, it runs concurrent forks anchored to a shared frontier candidate, so improvements stack faster than CORAL's independent agents or karpathy's strictly sequential loop. Third, every trial leaves structured artefacts (scores, event logs, and four LLM-authored analyses) that the next proposer reads back, where the baselines keep only flat attempt logs. Fourth, an adaptive controller pushes the proposer toward exploration after a stall and refinement after a win, with Predictive Hypothesis Reranking sitting on top to drop weak ideas before they spend budget.
What We Have Not Shown
The held-out curves demonstrate in-domain generalisation, not cross-domain transfer: a workflow tuned for AI-market signal extraction should not be expected to hold up on legal or biomedical text without rerunning the harness. The harness also only climbs the hill the grader defines, so a noisy training set or a miscalibrated judge will be faithfully over-fitted; we recommend at least 20 well-curated training items and a separate development split before a serious run. Cost is the biggest practical constraint. Every evaluation reruns the full pipeline against the full splits, the selected retrieval candidate alone consumed roughly 2.2 million input tokens, and a serious optimisation on a gpt-5.5-class model runs hundreds to low thousands of dollars per task. Finally, these numbers come from single runs rather than repeated trials, which is why we are sharing them as an engineering blog post rather than a formal study.
Conclusion
Tomoro Meta-Harness shows that autonomous code improvement can be made disciplined enough for enterprise use. The ingredients are structural hypotheses, predictive pre-filtering, isolated evaluation, held-out testing wherever the data allows it, and a full audit trail behind every promoted change. Together they give an engineering team a predictable path from a working seed pipeline to a measurably better one, and they give an operations owner a simple model: the upside of autonomous exploration, kept inside a strict, budget-aware framework with a person in the loop before anything ships.


