From Browser Wrappers to Constrained Computer Use
Why more capable agents push us beyond abstraction-heavy browser automation and toward constrained execution runtimes
Executive Summary
- What is computer use, and why does it matter? Computer use is a simple idea with broad implications: instead of asking models to answer questions, we ask them to operate software — navigating websites, filling forms, clicking through workflows, and completing tasks end-to-end, autonomously.
- This unlocks a large class of real-world tasks that are currently fragmented across interfaces, such as end-to-end bookings, e-commerce checkouts, multi-step travel planning, back-office workflows that have no clean API equivalent. These are not new problems. What is new is the feasibility of solving them with general-purpose models.
- Recent systems from Anthropic and OpenAI have demonstrated agents that don't just act, but reason about state, recover from errors, and construct task-specific solutions on the fly. This turns the browser into a general execution environment for agents but raises an immediate design question: how much of that environment should we expose to the model?
- Early systems answered by wrapping the browser into a fixed set of safe, predefined actions. As we'll argue in this post, that approach is reaching its limits.
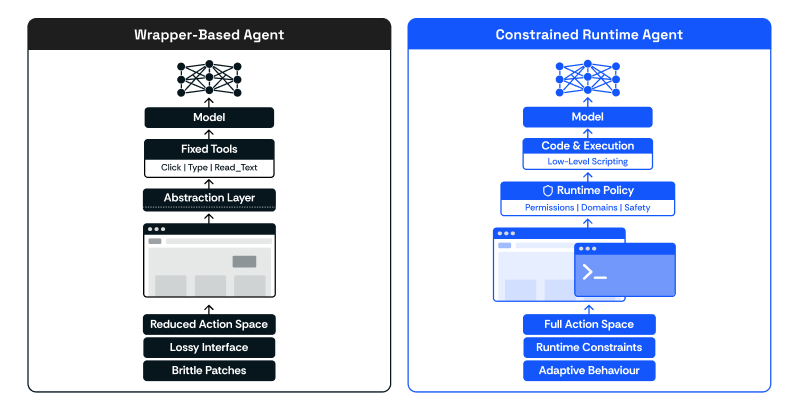
There is a familiar instinct when building browser agents: don’t trust the model too much.
So we wrap the browser. We expose predefined tools like click, type, scroll, select, and read_text. We simplify the Document Object Model (DOM). We reduce the action space. We try to make behaviour legible and controllable through abstractions we design.
This is a sensible starting point. It is also, increasingly, the wrong long-term architecture.
As frontier models improve, the limitation is no longer just that the model lacks tools. It is that we are forcing it to operate through abstractions that strip away too much of the underlying system. We compress a messy, dynamic environment into a fixed action interface, and then ask the model to perform well inside that loss of information.
That trade-off is becoming less attractive.
The shift we have been exploring is simple to describe, but significant in consequence. Instead of treating the agent as a selector of predefined actions, we treat it as a program synthesiser operating inside a constrained runtime.
The models got really good, and they no longer need your abstracted guardrails — they need the complete action space to design, execute, and iterate on the task until they achieve their goal.
This post is about that shift, from abstraction-heavy browser automation to constrained computer use, and what changes when you design systems this way.
Why Abstractions Break Down
The problem is not that fixed action interfaces are conceptually wrong. It is that the web does not cooperate with them.
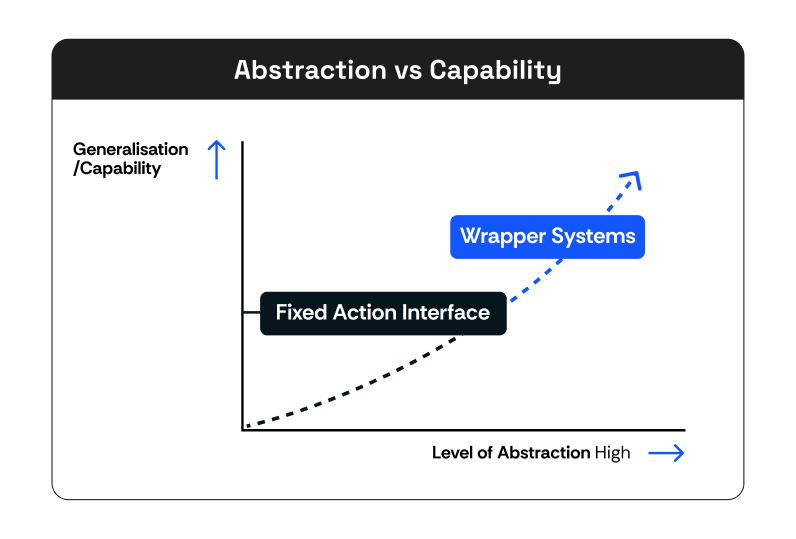
Modern interfaces are built on React, Vue, and Angular, with asynchronous state updates, synthetic event systems, and embedded third-party widgets that live in cross-origin iframes with their own lifecycles. A wrapper that says “type into this input” is only correct if the page agrees with your definition of typing. Many do not. Setting a value directly often bypasses the framework’s change detection entirely. The input appears filled. Validation never fires. The form remains broken.
You can patch this. You can add special cases for React inputs, dispatch blur events after focus, wait for network idle before reading state. Each patch is locally correct. Collectively, they accumulate into a system that is increasingly hard to maintain and increasingly specific to the sites you have already seen.
The deeper issue is that you are encoding assumptions about how interactions should work into the abstraction layer, and then discovering that the web has different assumptions.
What Happens When the Abstraction Meets a Real Flow
Consider a payment form embedded through Stripe or Adyen inside a cross-origin iframe. Your wrapper cannot reach it directly because it lives in a separate origin. Your read_text tool cannot observe its internal state. Your type tool cannot address its inputs. A wrapper-based agent hits a wall here. The abstraction was designed for the main document. The actual task lives somewhere the abstraction cannot see.
A similar mismatch shows up in less obvious flows. A framework-controlled dropdown may not respond to direct clicks at all, because the visible element is not the actual control. It may require a sequence of keyboard events to trigger the underlying state transition. From the outside, the UI looks clickable. The abstraction says “click.” Nothing happens.
Or consider a multi-step modal flow where the visible DOM updates lag behind internal state changes. The correct next action depends on a state transition that is not yet reflected in the elements your wrapper can see. A wrapper-based agent ends up acting too early or reading stale state, because it is operating on an incomplete view of the system.
In each case, the abstraction hides the signals the agent actually needs.
A model operating at a lower level — inspecting the live DOM, reasoning about frame boundaries, synthesising the interaction sequence for that specific surface — can navigate these situations. It is not that the model is inherently smarter. It is that it has access to the information that was stripped away.
The Architectural Shift
The change we have been working toward is simple to describe: instead of asking the model to select from predefined actions, we give it a lower-level execution surface and constrain that surface through runtime policy rather than abstraction design.
This design choice comes from a broader industry shift that is starting to favour lower-level primitive tools — ones that play into the agent’s innate capability of runtime correction and producing high-quality code, rather than hard-coded specific tools that are robust but strip the model’s ability to adapt to different environments.
Consider Claude Code’s success as a primary choice in many developers’ toolboxes, and the broader industry move toward terminal-based agents. Claude Code’s biggest advantage is not the model itself but the lower-level harness. Giving the model fewer, more modular, lower-level tools — i.e. the terminal — results in better tool-calling performance, mainly because the agent can reason and create custom scripts for the task at hand, rather than attempting to use generalised tools that pollute the context window.
In practice for the browser automation use case, this means the model can directly inspect live page state, traverse frames, and construct bespoke interaction code specific to the current interface, rather than mapping everything onto a fixed set of prebuilt actions.
The model behaves less like a selector and more like a runtime author. It inspects the current state, reasons about the interface, and synthesises the interaction logic for that specific situation. It can construct multi-step sequences, adapt to unusual flows, and validate outcomes before continuing. When an action fails, the model sees the underlying error and self-corrects. This is more powerful and more risky — but it is much closer to the actual shape of the problem.
Importantly, removing the abstraction layer does not make the system less disciplined. It relocates the discipline.
Work that used to live in wrapper design and edge-case handling moves into three places: the prompt (which becomes a form of operational training), the runtime (which enforces boundaries such as navigation scope, sensitive actions, and retry behaviour), and the evaluation layer (which assesses not just whether the task succeeded, but whether the intermediate steps were correct). Fewer brittle abstractions. Stronger surrounding systems.
The Surprising Consequence: Simpler Product Code, Broader Generalisation
One outcome of this shift is that the product code often becomes simpler, even as the overall system becomes more capable. Instead of encoding interaction patterns as reusable wrappers, the agent synthesises behaviour at runtime. You maintain a small set of powerful primitives and a constrained execution environment, rather than an expanding surface of specialised tools and edge-case logic.
This also changes how the system generalises. A wrapper-based agent generalises well to tasks that resemble the wrappers you have already built. A constrained runtime agent generalises to tasks that share an execution substrate, even when the visible interface is different.
For example, interacting with a search form, a booking flow, or a settings page may look completely different at the UI level. But underneath, they share patterns: reading state, triggering events, validating outcomes, handling asynchronous updates. A system that operates at that level transfers more naturally across tasks.
The reusable component is not the action list. It is the model’s ability to inspect state, act safely, and verify results.
Constrain, Don’t Over-assist
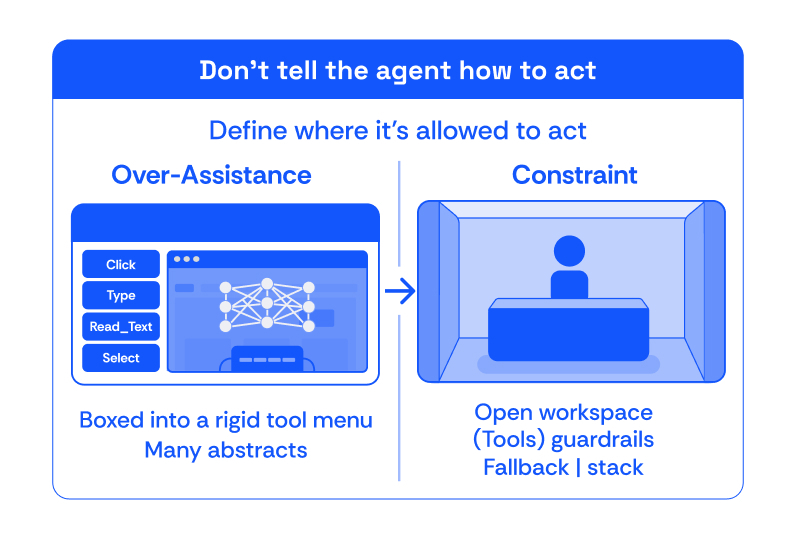
The clearest lesson from this work is that reliability does not come from giving the model more helper functions. It often comes from giving it fewer, more powerful primitives and constraining those primitives in the right ways. Over-assistance hardcodes assumptions about how a task should be done. Constraints define safe operating boundaries and allow the model to discover better local solutions.
A stronger execution surface also requires a sharper safety model. Once the agent is no longer constrained to a small set of predefined actions, it is effectively operating directly on real software. That changes the risk profile immediately.
There are four concerns to design for:
Data exposure. If the agent is interacting with real interfaces, it will often encounter sensitive information. That requires a disciplined approach to masking and access control. Data should only be revealed when necessary for execution, and logs and traces must be handled carefully so that observability does not become the most sensitive part of the system.
Execution scope. A powerful agent should not be able to operate arbitrarily. In practice, this means constraining where it can navigate, what domains it can access, and which systems it is allowed to interact with. These constraints should be enforced at the runtime level, not left as conventions in prompting.
Environmental trust. Modern interfaces can include instructions, content, or flows that are misleading or actively adversarial. Prompt injection through page content is a real attack surface. The system needs a clear hierarchy of instructions, validation checks, and termination conditions to prevent the agent from following unintended guidance.
Autonomy spectrum. Not all actions should be fully autonomous. In many production settings, it is important to treat autonomy as a spectrum. The system can be highly agentic in how it explores and executes, while still requiring approval for certain categories of actions.
The underlying principle is straightforward: giving the model more power requires increasing the strength of the surrounding system. Autonomy without policy is not production-ready.
The Reframe That Changed Our Thinking
We stopped asking: what are the right browser actions to expose?
We started asking: what can we do to provide the model a complete action space — and how do we create runtime policies around that which still make it safe?
That reframe changes what you care about. Action taxonomies and wrapper completeness matter less. Runtime policy, observability, and step-level evaluation matter more. Model capability and system design are not substitutes for each other. As models improve, the system's work becomes more important, not less.
Browser agents that work in demos often succeed because the task is narrow and the environment is cooperative. Production systems require something different: constrained execution, instrumented behaviour, and evaluation that can distinguish a correct outcome from a lucky one.
Closing Thought
Less wrapper design. More systems engineering.
And while we focused on browser agents, this points to a broader way of thinking about computer use as a systems discipline.


