How We Built Our Own Smart Recording Discovery Solution With Codex
Turning company meetings into searchable knowledge so shared insight is no longer hidden
Executive Summary
- Recorded meetings are an underused knowledge asset. They're hard to search, time-consuming to revisit, and siloed across team drives, meaning valuable insights often go unnoticed.
- In a single-day hackathon, a team of three built Callombia. It's an internal platform that automatically transcribes, tags, summarises and clips recorded calls into a searchable, YouTube-style repository accessible across global offices.
- The solution, all built with Codex, uses semantic search powered by OpenAI embeddings and cosine similarity to surface relevant moments even when exact keywords aren't used, with a RAG chatbot and notification system layered on top.
- What once would have taken weeks was delivered in seven hours, demonstrating how AI-native development with coding agents like Codex can dramatically compress the product development lifecycle and unlock genuine business value from internal hackathons.
If you are like me, you rarely have the time (or the attention span) to listen back to recorded meetings. That’s often because it involves searching through disorganised team drives, skipping through sub-par small talk and trying to actually listen while firing off emails and messages.
But perhaps it doesn’t have to be that way? Maybe we could build something that completely changes recorded meetings? That was the thinking behind our recent Hackathon project.
In just a day, 50 of our engineering, delivery and ops team tackled a number of problem statements sourced across the business, from scaling hiringops, streamlining SoW creation, understanding project health, live protoype generation and surfacing insights within recorded meetings.
In this Codex-based hackathon, we built Callombia. Callombia is the YouTube of Tomoro that turns every call into a living searchable asset. Each call is automatically transcribed, tagged and summarised before being snipped into thematic clips and added to a repository grouped by channel (clients) and topics (areas of AI specialism). This allows any one team member from London, Edinburgh, Singapore and Australia to instantly access the moments in calls they care about.
A familiar, on-brand user interface makes content discovery intuitive and a semantic search (and of course RAG AI chatbot) helps people find specifically what they are looking for. Adding a notification system also allows our colleagues to subscribe to certain topics and be notified if any new clips get released that are relevant to them.
But what’s cool about Callombia isn’t the product, or the £2k prize for winning the Hackathon (flex), but the fact that we could build all of this in just seven hours with two engineers and a delivery lead. That wasn’t possible a year ago. Coding agent improvements have vastly accelerated the end-to-end process of product development and this Hackathon proved a great testing ground to understand its jagged frontiers. So, how did we use Codex?
Planning Our Solution
Rather than just writing a load of requirements, we started by sharing our collective view (as a prompt) on the problem space and vision for Callombia. By being intentionally nondescript we let the model do the work and allowed it to think creatively:
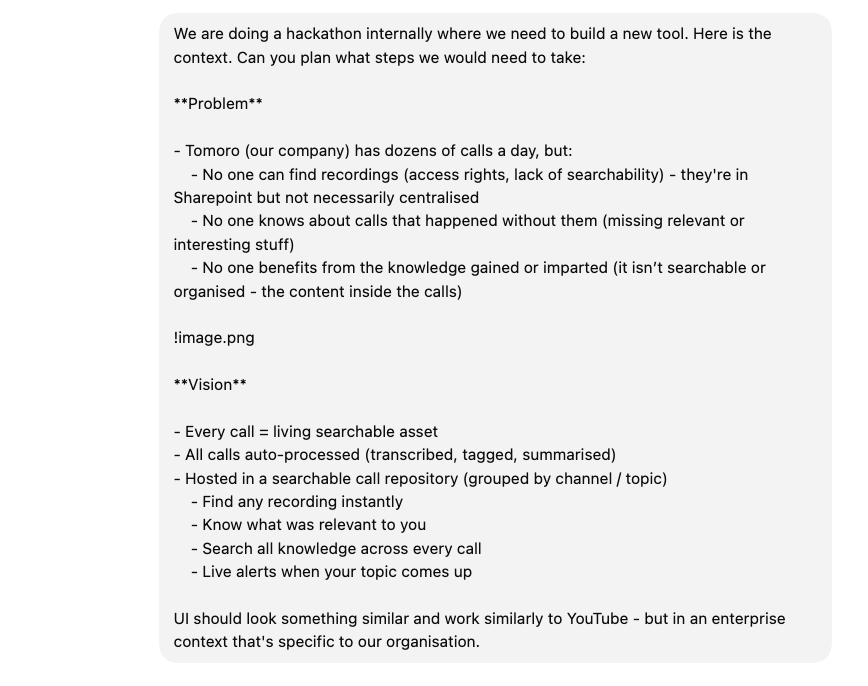 After 10 minutes of back and forth, we turned on Plan Mode to narrow down requirements and inform the technical part of the build. Plan Mode feels like answering questions from that annoying friend who has (helpfully) thought through every possible scenario. After agreeing things like number of videos, semantic or keyword search and what architecture we will use - it created a markdown file that formed the basis of the project from there.
After 10 minutes of back and forth, we turned on Plan Mode to narrow down requirements and inform the technical part of the build. Plan Mode feels like answering questions from that annoying friend who has (helpfully) thought through every possible scenario. After agreeing things like number of videos, semantic or keyword search and what architecture we will use - it created a markdown file that formed the basis of the project from there.
Building The Core Components
Once we had a plan, the next step was building the core components that would make Callombia actually work. That meant creating a pipeline from recorded calls to searchable assets:
- Ingesting videos and transcripts,
- Chunking them into meaningful moments,
- Enriching them with summaries and tags,
- Exposing them through APIs that the frontend could consume.
Ed focused more on getting the raw recordings and transcript data into a usable format, while Nico focused more on the retrieval layer that would make those moments discoverable. With Codex, both of them were able to stand up the data models, extraction scripts and backend plumbing much faster than we could have done manually. That gave us much more than a transcript attached to a video. It gave us moments: the Tesco section, the strategy update, the hiring discussion, the specific 90 seconds in a call that someone actually wants to watch.
That retrieval layer was where things got especially interesting. We wanted someone to type something like “financial performance”, “Tesco roadmap” or “conversation evals” and be taken to the most relevant clips, even if those exact words were never said. To do that, we created chunks with timestamps, summaries, transcript text and metadata. With a clear architecture in mind, and a lot of help from Codex, we combined the topic, summary, and transcript into a single input and used OpenAI’s text-embedding-3-small model to generate embeddings for each chunk. We stored those embeddings in our database and used cosine similarity to compare a user query against every chunk, which gave us a semantic retrieval layer rather than a simple keyword search.
This worked extremely well for accuracy and gave the product its “magic” feeling during the hackathon demo. At the same time, we knew this approach would not scale forever if the number of videos kept growing, because comparing every query against every chunk would eventually become too expensive. The natural next step would be to introduce more efficient retrieval strategies, such as Hierarchical Navigable Small World, to reduce the number of comparisons and keep latency low as the corpus expands. Once this feature was working, Callombia started to feel less like a media library and more like a knowledge system.
As with all good hackathons, that part needed iteration too: the first chunk boundaries were too rough, some timestamps needed tightening, some tags were too broad and transcript and recording files did not always line up neatly. But that is also where the value showed up. Codex let us refine the system quickly instead of getting stuck in setup and rework. By the end, we had a backend that could power clips, snippets and genuinely useful semantic search, which was the point where Callombia started to feel like a real product rather than just a hackathon demo.
Frontend Build and UI
While Ed and Nico built the ingestion and the intelligence layer, I built the frontend. Using our full stack template, I was able to quickly spin up a first version of the website without writing a single line of code. After asking it to open the website locally in my browser, I would provide simple bullet-point feedback to iterate the design to what I was looking for.
After an hour or so of back and forth, I had something that I was pretty happy with; all without any experience in UI or design. While the end product is definitely not perfect, it’s a pretty good first version that lets people understand the product.
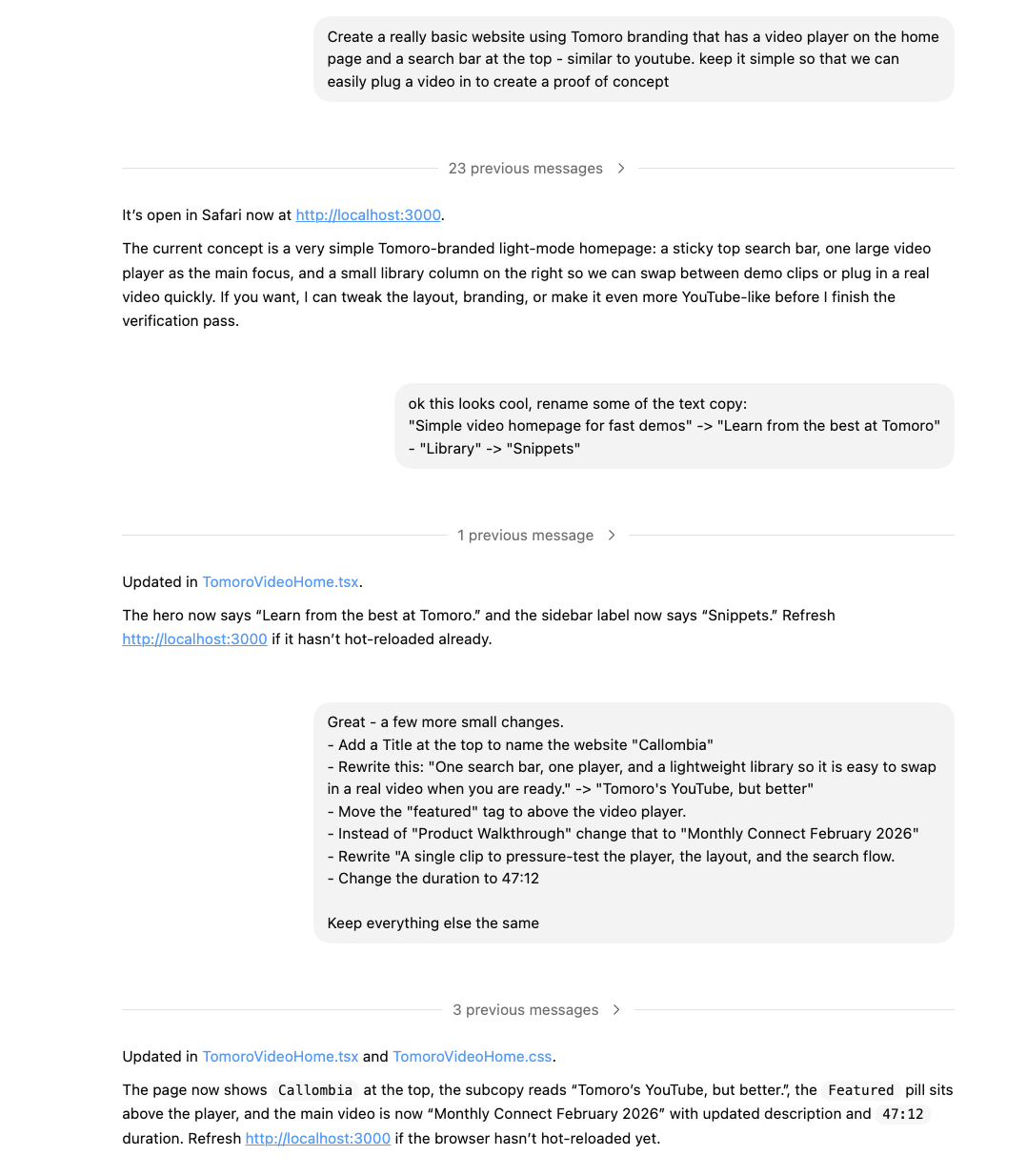
Gluing All The Code Together
To make sure we had something at the end of the day, we had split the work amongst ourselves. Obviously after a few hours of semi-independent work we all had our own local branches with a ton of conflicts.
Rather than take the time (that we didn’t have) to diligently go through and resolve conflicts, we decided to just let Codex loose on the repos and fix the conflicts by itself. While we wouldn’t endorse this for enterprise-grade software development right now, it’s incredible to see the effectiveness in a low stakes environment and saved us many hours.
The Entire Demo
The final part of the hackathon was recording the demo of Callombia for the judges. While instinct made us want to open up Loom to handle the recording, we thought this might be a real test for Codex and something a bit outside of its current capabilities. So… We wrote a prompt, gave it a link to the Callombia website, appended a recording of my voice on OpenAI’s developer platform and asked it to do the rest.
The first attempt was very impressive - it had written a demo script, recorded the screen, added my voiceover and pretty much hit the brief. The only thing that we weren’t immediately happy with was syncing the voiceover with the demo recording, so we asked it “MANDATORY: align the voiceover exactly with what is being shown in the demo. There was misalignment (e.g. on the chat page). Triple check alignment of voiceover and the screen-recorded demo at the end. Match it up through whichever means possible.”
In response to that request, Codex split the voiceover and recording into smaller sections, executing the task pretty much flawlessly just in time for 5.30pm and beer/pizza to celebrate.
Becoming More AI-Native
We know Callombia solves a problem most businesses have. Attending every call in a rapidly scaling company is difficult, but the nuggets of wisdom shared on these calls are invaluable. Now we just need to get it into Production.
But there is a greater lesson in being AI native here and the benefit of committing engineering and product nouse to tackling shared problems. By breaking out of our usual working cycle, collaborating across teams and all within in a semi-competitive environment, we ended with a number of solutions that, with some tweaks, could be put into production. Done on a regular basis, we can ensure we’re just as slick internally as the solutions we build for customers.


