Agentic Coding Won't Speed Up Your Team, But Fixing the Review Loop Will
The near-term future of agentic engineering is unlikely to be one giant leap to full autonomy.
Executive Summary
- Most teams adopting agentic coding shift bottlenecks from generation to review, net velocity gain is close to zero without fixing the loop.
- In large-scale CI environments (millions of nightly tests, hundreds of engineers), the highest-value agent task is ownership routing and triage, not code generation.
- Useful agent output survives scrutiny and explains causality, not just pattern matches.
- Designing the evidence-gathering and context-assembly layer matters more than the generation layer.
Most discussion of agentic coding still starts with a simple promise: writing more code, faster.
Sometimes that expands into a more ambitious vision of agents planning work, opening PRs, and shipping changes with minimal human intervention. But for most engineering teams, the clearest near-term value is narrower. It is about reducing the cost of iteration.
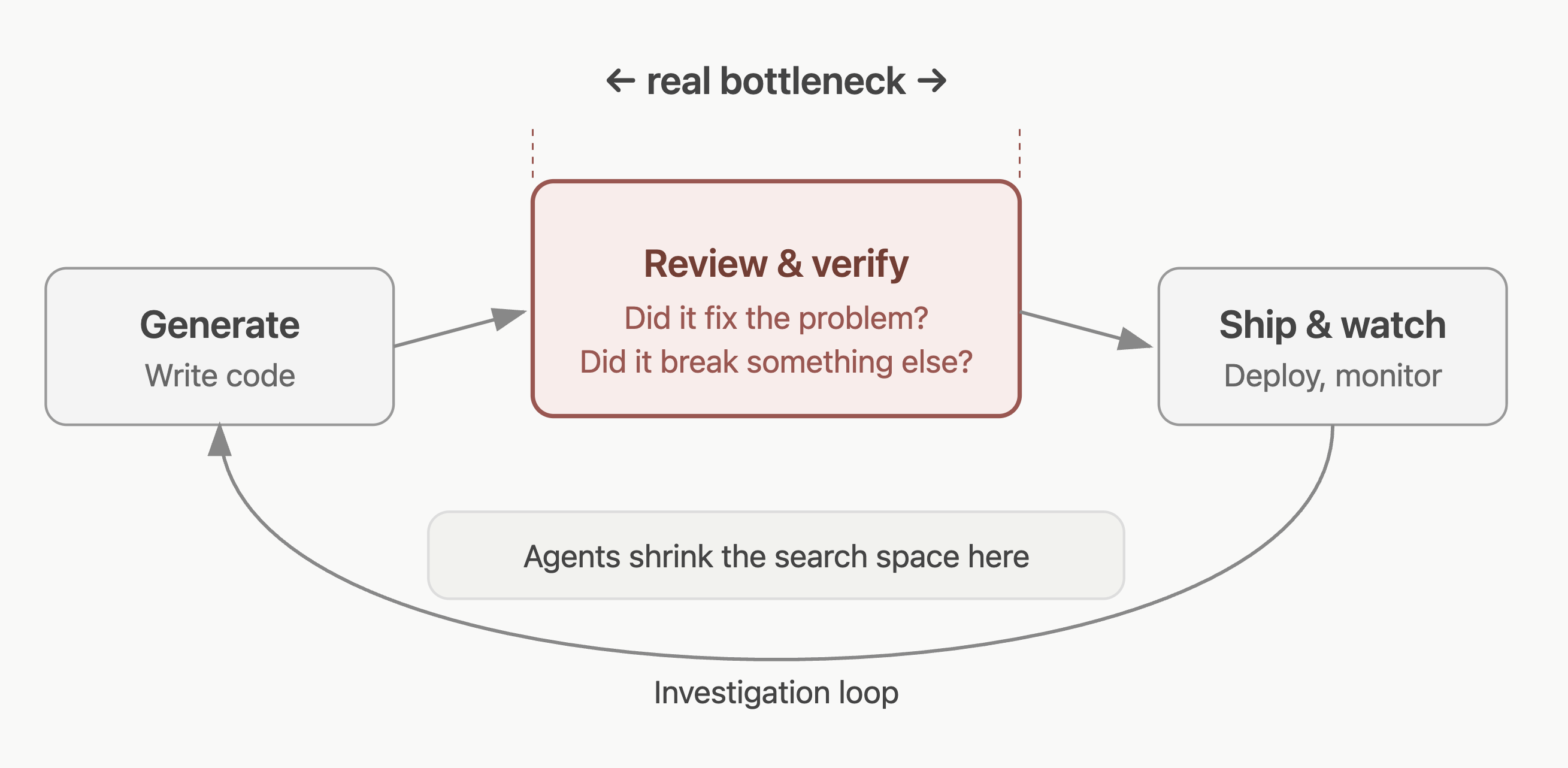
Software delivery is not just code generation. Writing code is only one stage in a longer loop that includes review, testing, deployment, and investigation when things go wrong. Most teams that adopt agentic coding without redesigning the review loop just move their bottleneck downstream.
Speeding up generation on its own does not automatically make a team faster. It can just shift more effort into review, verification, and trust.
The Real Bottleneck is Confidence
In many engineering environments, the expensive part is not producing a first draft but getting to confidence.
Did the change actually fix the problem or improve the system? Did it introduce a regression somewhere else? Is the failure in the code, the environment, the tests, or a dependency? Is the proposed fix addressing the cause, or only the visible symptom?
Agents can help here, not because they replace engineers, but because they can do a structured first pass across messy evidence: inspect logs, compare recent changes, summarise relevant signals, trace likely causes, run checks, and return something a human can interrogate.
In many teams, the highest-leverage use of an agent is not generating code from scratch. It is shrinking the search space around a problem before a human spends hours doing it manually.
Why Review-heavy Workflows Fit
This is especially clear in large-scale debugging workflows. Imagine nightly CI running millions of tests across codebases touched by hundreds of engineers (a reality for one of our clients). When something fails, ownership routing is difficult. The problem might sit in the application code, a dependency, the test harness, or somewhere else in the stack. Logs can run to gigabytes, and the first team to see the issue is not always the team that owns it.
That kind of workflow does not naturally call for one agent to write the fix. It is built for a system that narrows the problem space quickly.
A useful pipeline might fetch logs, select the relevant evidence, summarise what matters, inspect code in a sandbox, and produce a structured root-cause analysis with confidence scoring, traceability, and suggested next steps. To generate a confidence score, a subject matter expert marks the agent’s initial output. This is then fed into an LLM-as-a-judge to automate scoring moving forward while retaining alignment with a human judgement.
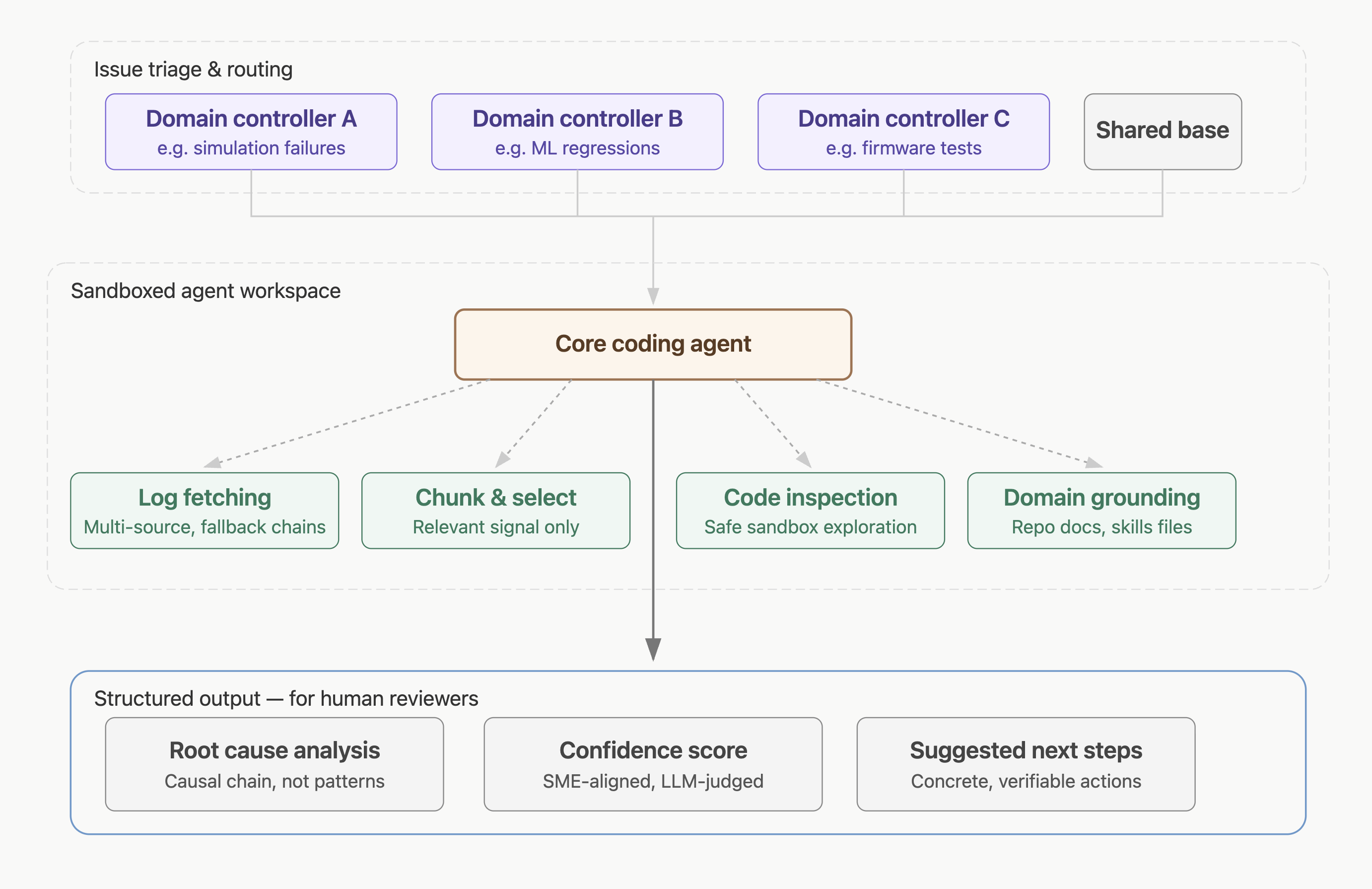
The point is not to eliminate engineering judgement but instead give reviewers a stronger starting point. Regression triage, PR review, test repair, release validation, and post-deployment investigation all share the same shape. They are evidence-heavy, review-heavy, and full of ambiguity. They do not ask an agent to replace the engineering process, just to help move the process forward.
Look For the Improved Workflow, Not Output
This is also why teams should be careful about how they assess these systems.
The wrong question is whether an agent can produce something impressive in isolation. The better question is whether it improves a real workflow without creating drag somewhere else.
That means looking at whether the output is specific enough to verify, whether it explains causality rather than just pattern-matching, and whether it makes review easier rather than harder. A plausible answer is not the same thing as a useful one. In practice, teams trust agent output when it survives scrutiny and gives them something concrete to check.
The Hard Part is Designing the Loop
The deeper lesson is that useful agentic systems depend on more than generation. They depend on how evidence is gathered, how context is assembled, how outputs are checked, and how uncertainty is surfaced to the reviewer.
That is why the near-term future of agentic engineering is unlikely to be one giant leap to full autonomy. It is more likely to be a set of tightly designed loops where agents help teams inspect, review, verify, and refine their work with less wasted effort between steps.
That may be less dramatic than the broader autonomy story, but it is much closer to how useful systems are actually adopted.


