Conversational Design: Five Patterns to Shape Customer-facing AI Experiences
What held up in production when the goal wasn’t just functional accuracy but better dialogue
Executive Summary
- Most prompt engineering focuses on accuracy and instruction coverage. The biggest gains in production come from treating dialogue itself as the core design problem.
- Specifying trigger-and-action intentions guides the model on how to decide, rather than giving it a script it cannot escape. Position in a prompt is an instruction in itself. Identity goes first, behavioural nuance in the middle, hard constraints last, and anything genuinely critical goes in both places.
- Writing the prompt in the target voice, rather than describing it, is one of the highest-impact changes available.
- The most coherent agents are those whose prompts treat different conversational moments as distinct interactions, each with its own appropriate shape, while remaining recognisably the same voice throughout.
- In some cases, separating agents that think from agents that speak produces more coherent, grounded responses and prevents internal reasoning from leaking into replies.
We previously introduced a new prompting paradigm based on insights from the fields of linguistics and cognitive psychology. We wrote about the importance of creating a clear, well-bounded problem space within which our agent can operate, and how that problem space needs to capture the meta-task of dialogue inherent to customer-facing AI.
Now, we’ll take a look at some practical ways our prompts have begun to change as we’ve attempted to take these principles into production.
Across hundreds of prompt iterations in live customer-facing systems, the biggest gains haven’t come from adding more instructions, piling on examples, or following typical prompt engineering norms. Instead, they’ve came from embracing dialogue as the heart of the problem.
A number of effective techniques have emerged through continuous exploration and testing. We’d change a prompt and watch where the conversation succeeded or failed, tracing failures back to the effectiveness of guidance, prompt structure, and our use of language. The result is a handful of repeatable patterns that change how the agent interprets its role in the conversation, how it decides its next move, and how consistently it holds voice across shifting contexts.
What follows is not a universal framework or a claim that prompting is now “solved”. It’s a distillation, into five patterns, of what held up in production when the goal wasn’t just functional accuracy but better dialogue: responses that feel coherent, natural, and consistent enough to carry a brand.
1. Split Thinking from Speaking
While there are many ways to structure an agentic system, multi-agent orchestrated workflows remain popular. Across such systems in particular, the most consistent improvement we made was separating the agents that think from the agents that talk.
Intent orchestration, classification, knowledge extraction and tool use are all back-of-house operations. Customer-facing responses are front-of-house. When the same agent does both in the same turn, internal reasoning and logic can leak into replies. Responses become hedged, over-qualified, or structured around the logic of the process rather than the needs of the person.
The Relationship Between Front and Back of House in a Multi-agent System
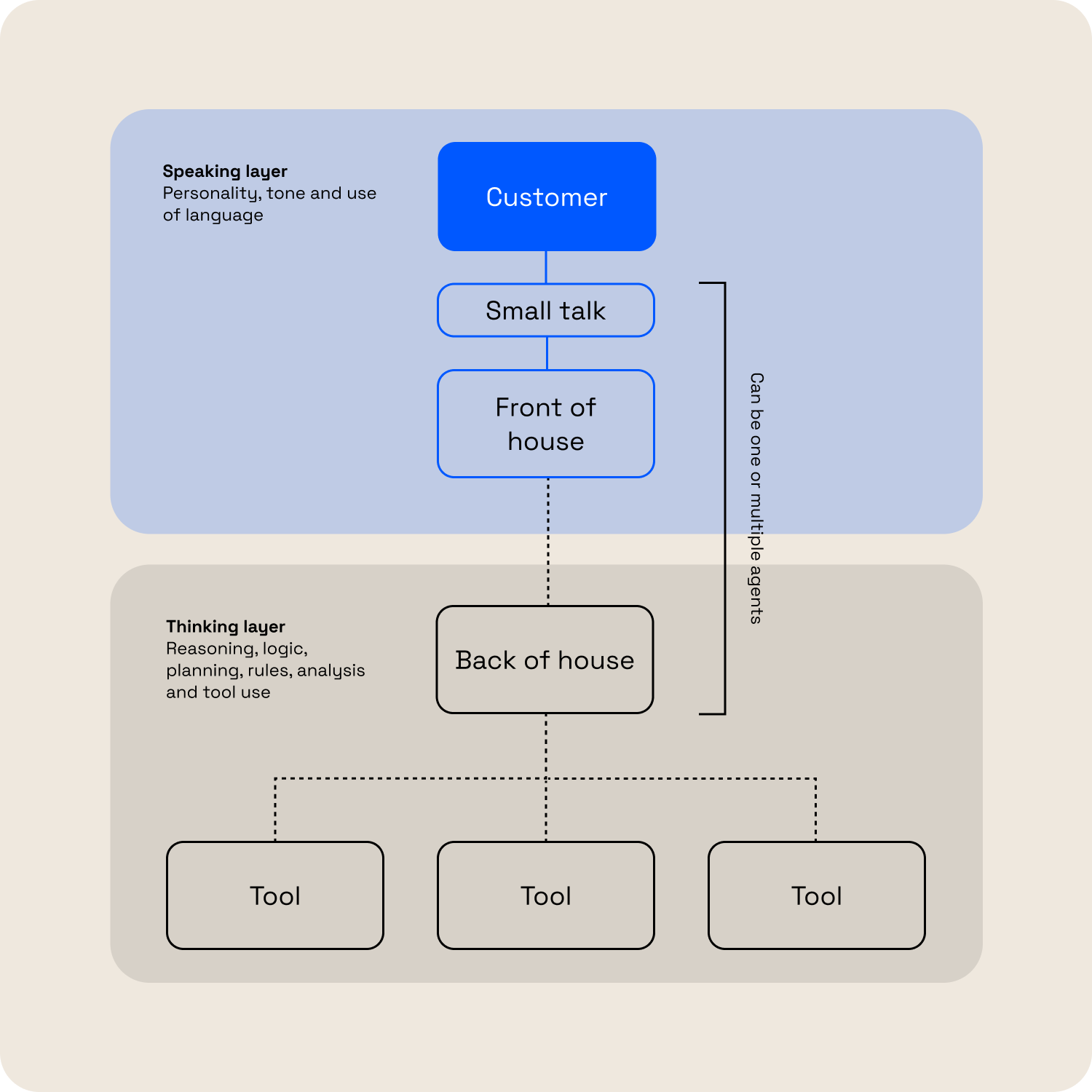 Splitting these responsibilities cleanly means the speaking agent receives only what it needs: a summary of the conversation so far and the relevant output from an upstream agent, for example. From there, we ask it to do one thing — paraphrase what it understands, then respond.
Splitting these responsibilities cleanly means the speaking agent receives only what it needs: a summary of the conversation so far and the relevant output from an upstream agent, for example. From there, we ask it to do one thing — paraphrase what it understands, then respond.
That single constraint does a surprising amount of work. It keeps replies grounded in the actual conversation, prevents context reset, and produces something closer to what we call "delivering the delta.” Ultimately, the agent is adding only the smallest new thing that genuinely moves the user forward.
The decision about what type of response to give matters too. We found that asking the speaking agent to select a move type before writing anything — answer, clarify, redirect, hold — reliably reduced the most common conversational failure: not bad prose, but the wrong response entirely.
It’s worth noting that the latest frontier models are starting to challenge the premise of this pattern under the right conditions. Nonetheless, many builders still rely on smaller or older models for a variety of reasons, and in those contexts we certainly recommend dividing your back-of-house and front-of-house concerns.
2. Use Implementation Intentions Over Examples
For non-reasoning models, few-shot examples work because they're concrete, they're fast, and models respond to them well. The problem is overfitting. Give a model an example and it latches onto the words, the rhythm, and the shape, continually producing close cousins of the same response even when the situation has changed.
You've inadvertently written a script from which the model can’t escape.
Implementation intentions or heuristics are a more durable alternative. Rather than showing the model what to say in specific scenarios*,* we provide a broader trigger and action pair: if X happens, do Y.
The key difference is that, instead of narrowing towards X and Y one example at a time, whereby they become increasingly rigid, we draw a firm boundary around each through an instruction so precise that it renders examples redundant. This keeps the agent responsive to real conversational variation rather than pattern-matching to a template.
In practice that looks less like examples and more like executable rules of thumb:
- If a key detail is missing, ask one clarifying question.
- If the answer isn't supported, say so directly and offer the best available next step.
- If the request hits a guardrail, decline briefly and redirect without ceremony.
It's not glamorous, but it’s significantly more robust than a library of sample responses, because it teaches the model how to decide rather than what to repeat.
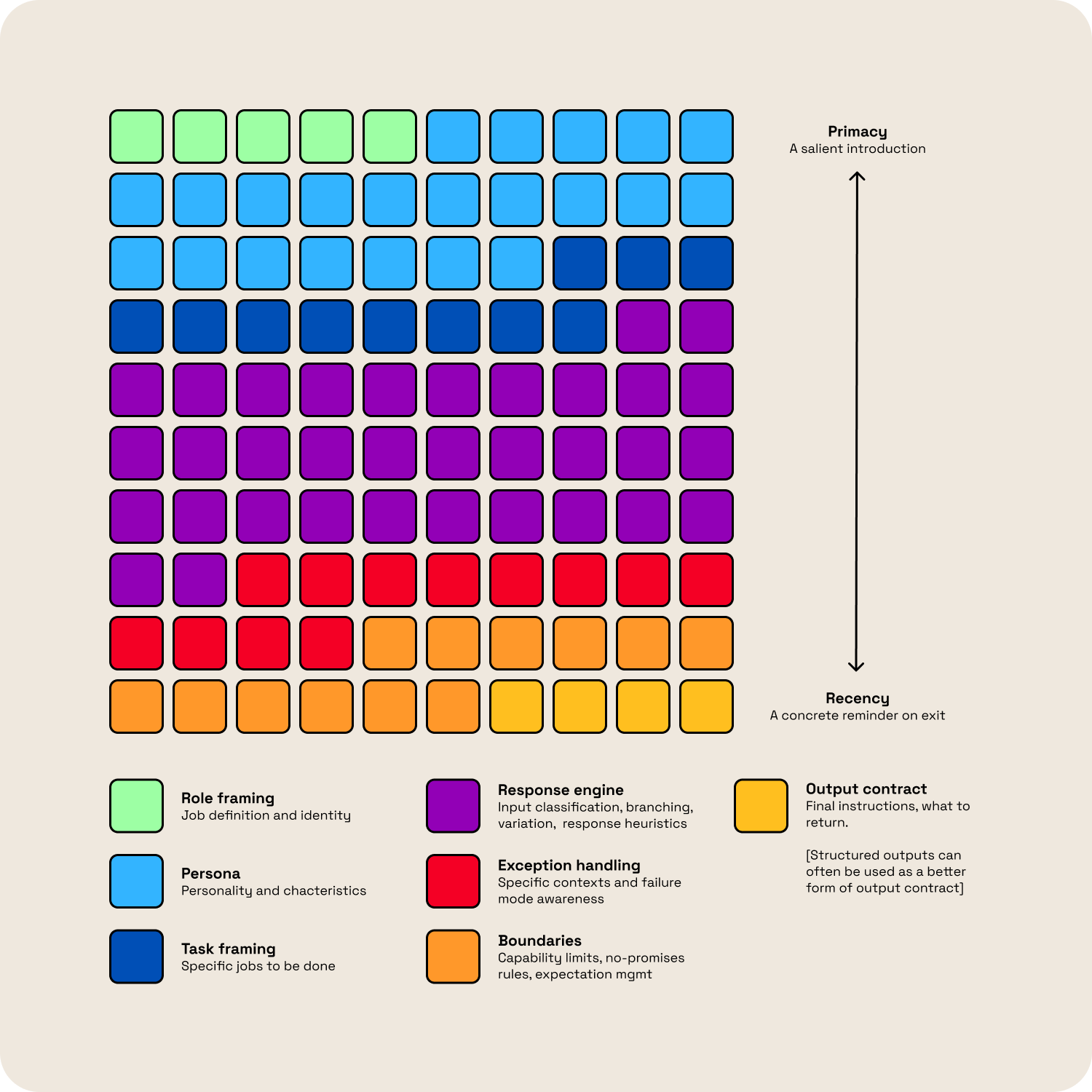
3. Treat Position as an Instruction
Where something sits in a prompt shapes how much weight it carries. This is a consistent pattern we've observed across models and deployments. The beginning and end of a prompt are disproportionately salient. What sits in the middle is nuance, which is exactly where nuance belongs.
We structure our prompts with that in mind. The agent's role and sense of self goes at the top so we’re establishing identity before anything else. The middle carries the behavioural detail: how the conversation is likely to unfold, the heuristics that guide responses, and the range of situations the agent needs to handle. Hard constraints and non-negotiables go at the bottom, where they become “front of mind”.
For anything genuinely critical, we put it in both places. A specific output rule — say, a firm instruction around punctuation or formatting — can routinely get lost if it only appears once in the middle of a dense prompt. Repeated at the end, it holds.
Worth noting on the point of recency is that structured outputs, when used, are effectively the very last instruction in your prompt. Description fields in your structured outputs have a qualitative bearing on responses, forming a stronger output contract than the rest of a prompt.
The Anatomy of a Front of House Prompt (if the Prompt Were 100 Tokens)
4. Make the Prompt the Example
We’ve learnt not to use few-shot examples for tone-of-voice either, and this is one of the highest-impact changes we’ve made to our customer-facing agents.
Instead, we write the entire prompt in the target voice. Not a description of the voice, not a set of adjectives that approximate it, but the actual voice, in full prose, from the first line to the last. The prompt becomes the demonstration. We call this “anti-scriptness”: guiding the model to mimic it’s input, while allowing it to use a greater range of language and phrases that exist within the same “ballpark” as the prompt itself.
This is how we prompt for variety within a coherent voice. It’s part of our strategy for bringing dialogue to the heart of the task for any agent, without having to spend explicit instructions, which we’re trying to keep to a minimum.
If we do use explicit examples on tone-of-voice, they’ll exemplify "what not to do.” For example, “No em dashes. Ever. No clichés. No policy dumping. No over-explanation when a single sentence will close the loop.” Negative constraints are both more precise and less restrictive than positive aspirations, because they name the failure modes the model is most likely to drift toward.
Formatting matters here too and sets the tone of a response. A prompt full of bullet points, headers, and bracketed instructions guides the model toward a more organised, clinical output. If the output is meant to feel like a conversation, the input shouldn't look like a short-hand specification document.
5. Register Matters More than Personality
Most prompting for tone collapses into personality. Providing a set of adjectives meant to describe how the agent should sound. Warm. Professional. Friendly but concise. These aren't wrong, but what actually governs how a voice lands in conversation is register: how the same underlying character behaves across different social situations.
A holding message while a query is being processed shouldn't sound like a final answer. A guardrail response shouldn't carry the same energy as small talk. A customer who's frustrated shouldn't receive the same level of charm or humour as one who's browsing casually.
Same prompt. Different registers. No examples
 The agents that feel most coherent aren't the ones with the most defined personality. They're the ones whose prompts treat different conversational moments as distinct interactions — each with its own appropriate shape, while remaining recognisably the same voice throughout.
The agents that feel most coherent aren't the ones with the most defined personality. They're the ones whose prompts treat different conversational moments as distinct interactions — each with its own appropriate shape, while remaining recognisably the same voice throughout.
This is the difference between brand voice and conversation design. Brand voice often describes character, while conversation design decides how that character behaves when situations shift. Getting that right means we're not just copywriters working on AI outputs. We're designing how a voice moves through a conversation.
Dialogue Driven Prompting
You’ll notice that none of these patterns is technically complex. That’s partly the point. The architecture of an agentic system matters, but when it comes to conversational quality you’ll need to spend significant time on the design and refinement of your prompts.
The gap between purely functional and genuinely conversational AI isn't closed by technical design, it's closed by a clearer understanding of how language and attention function in human dialogue and by bringing dialogue to the heart of the problem space for your agents.
For AI product teams, engineers, and experience designers, conversational design deserves the same rigour as technical excellence in customer-facing AI. For the people on the other side of these conversations, there is no model, no multi-agent collaboration, no tool call — there is only an interaction that either feels right or doesn't. One that either builds confidence or erodes it.
In the end, nobody experiences the architecture. They experience the conversation.
The conversation is the product.


