Responses are the Easy Part: What We’ve Learned Building Real-time Voice Experiences at Scale
Timing, interruption, silence and recovery shape the experience as much as words
Executive Summary
- Realtime voice gives people a fundamentally different way to interact with AI-powered applications. Instead of typing or navigating menus, users speak naturally and receive responses with real-time pacing and emotional context.
- Building a great realtime voice experience is about coordinating a live interaction. This is where the real product work starts. The realtime experience is immediate and lifelike; building an application that sustains that is a distinct engineering challenge.
- The model is only one part of the system. Production applications need voice-native infrastructure, a clear separation between conversational flow and deeper reasoning, and event-driven control to manage the session as it unfolds.
- Guardrails and evaluation are where much of the remaining difficulty lies. Safety checks need to keep pace with live audio, and ephemeral conversational qualities like timing, tone, and conversational flow are challenging to assess with traditional evaluation strategies.
Introduction: Realtime Voice as a Product Surface
Most voice-enabled AI applications today still work the same way: speech goes in, text comes out, a model thinks, and a synthesised voice reads the answer back. It works. But the interaction feels like what it is: a pipeline, not a conversation.
Realtime voice changes that. Users speak naturally and receive responses that carry pacing, tone, and emotional context. The experience is faster and more fluid than chained speech-to-text pipelines, closer to talking with a person than operating a system.
We have seen this open up product surfaces that pipeline architectures struggle with. Realtime voice agents can handle customer service interactions that would otherwise need lengthy, restrictive IVR menus and department transfers. They can coach, onboard, assist with accessibility across mediums, and more. Anywhere spoken conversation is an advantage over text-based interfaces, realtime voice is worth building for.
Chained vs Realtime: What Changes Under the Hood
Most voice-enabled applications use what is known as the ‘chained approach’: a pipeline of separate models for speech-to-text, language processing, and text-to-speech. These systems work well and open up a wide range of opportunities, but the audio sits only at the edges. The discrete steps add enforced structure and latency, producing an interaction that feels less natural than a real conversation.
Realtime voice takes a different approach. Rather than relying on distinct models for listening, thinking and speaking, a single model handles all three natively, understanding and generating both audio and transcripts simultaneously. Input and output happen continuously, allowing the system to respond with natural timing and emotive responses that maintain the realistic rhythm of a live conversation. The result is that timing, tone, and interruption handling become a central part of the product.
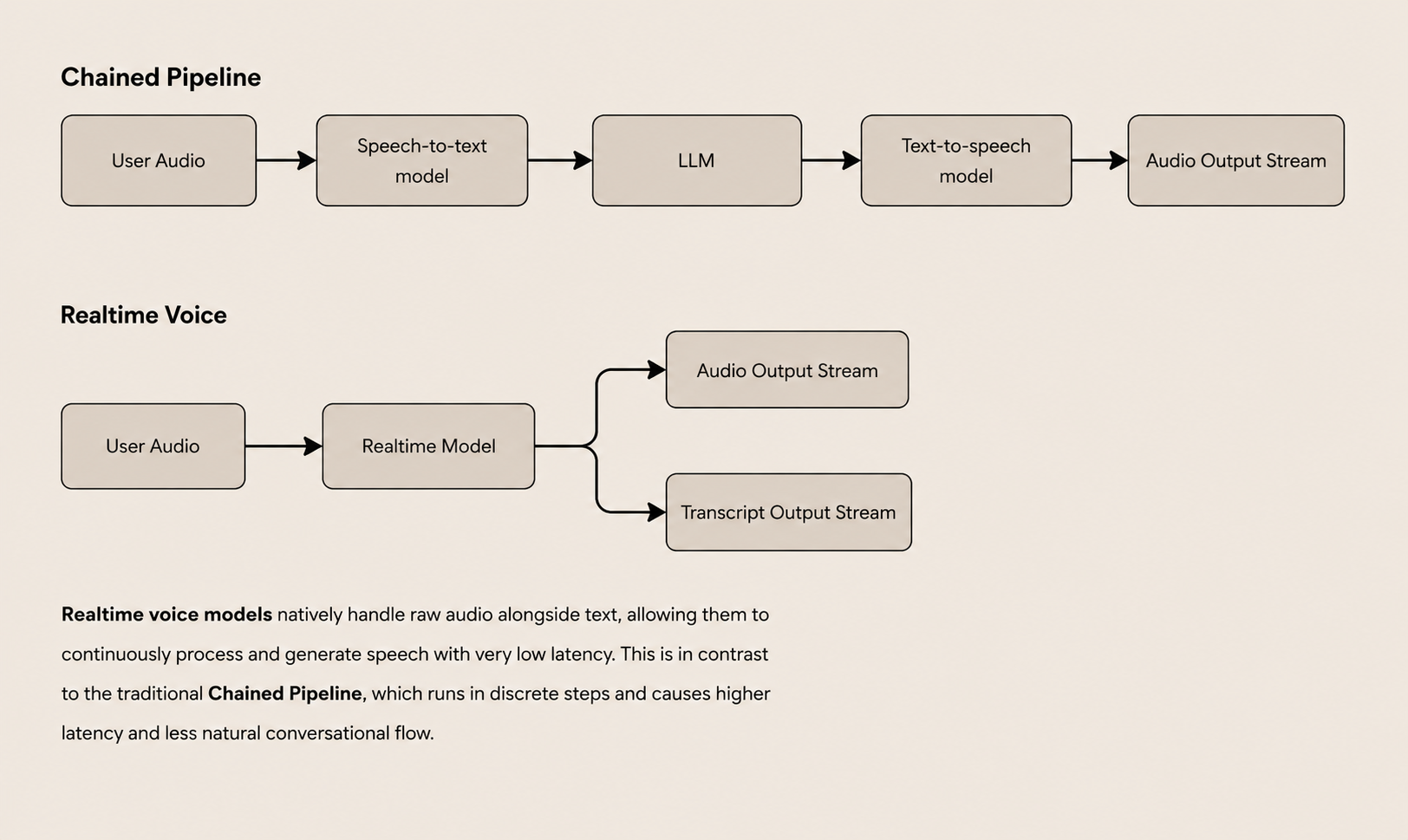
The realtime experience is attractive because it feels immediate; it is hard because nothing waits its turn. Supporting it requires more than fast and accurate audio generation. The difficult part is everything else. The model operates inside a live session; everything around it (state, safety, orchestration, and control) needs to operate alongside the conversation at the same live pace.
In a chained voice application, turn-based conversations give you a clean back-and-forth structure. The user speaks, the system responds, and the next step begins. Realtime voice does not give you that structure. Both parties can be talking at the same time, or neither speaks and there’s silence. A user can interrupt mid-response or ask a follow-up before the system has finished speaking. Interruptions stop being edge cases and become a core interaction pattern.
This pattern is what makes realtime applications fundamentally a coordination problem, and why the system around the model matters as much as the model itself.
What You Need in Production
Supporting this kind of system at scale requires designing specifically for live interaction, which comes in three parts that repeatedly show up in systems that make it into production.
Voice-native Infrastructure
Realtime voice sessions need to handle audio streaming, turn-taking, interruptions, connection lifecycle, and agent execution. Depending on where the application is deployed, telephony support may also be required. These are foundational parts of the experience and central to scaling the application.
A voice-native session layer is the first requirement. Realtime Communication (RTC) frameworks give the application somewhere to manage participants, stream audio and run agents in a telephony environment. In our experience, Livekit in particular has been helpful, providing a low-latency WebRTC stack with high-quality noise cancellation and jitter reduction out-of-the-box. Implementing this layer yourself is rarely worth the added complexity.
Separate Speaking from Thinking (at least for now)
A multi-agent architecture for realtime voice is fundamentally about separation of concerns.
Realtime voice models are highly effective at conversational audio streaming, but they are not optimised for deeper reasoning. Tasks like tool calling, retrieval, or structured decision-making benefit from execution by a different model.
A useful pattern is the responder–thinker architecture.
The responder is the realtime voice agent. It is responsible for maintaining the live interaction: listening, speaking, handling interruptions, and preserving conversational flow. Its design prioritises responsiveness, clarity, and emotional continuity.
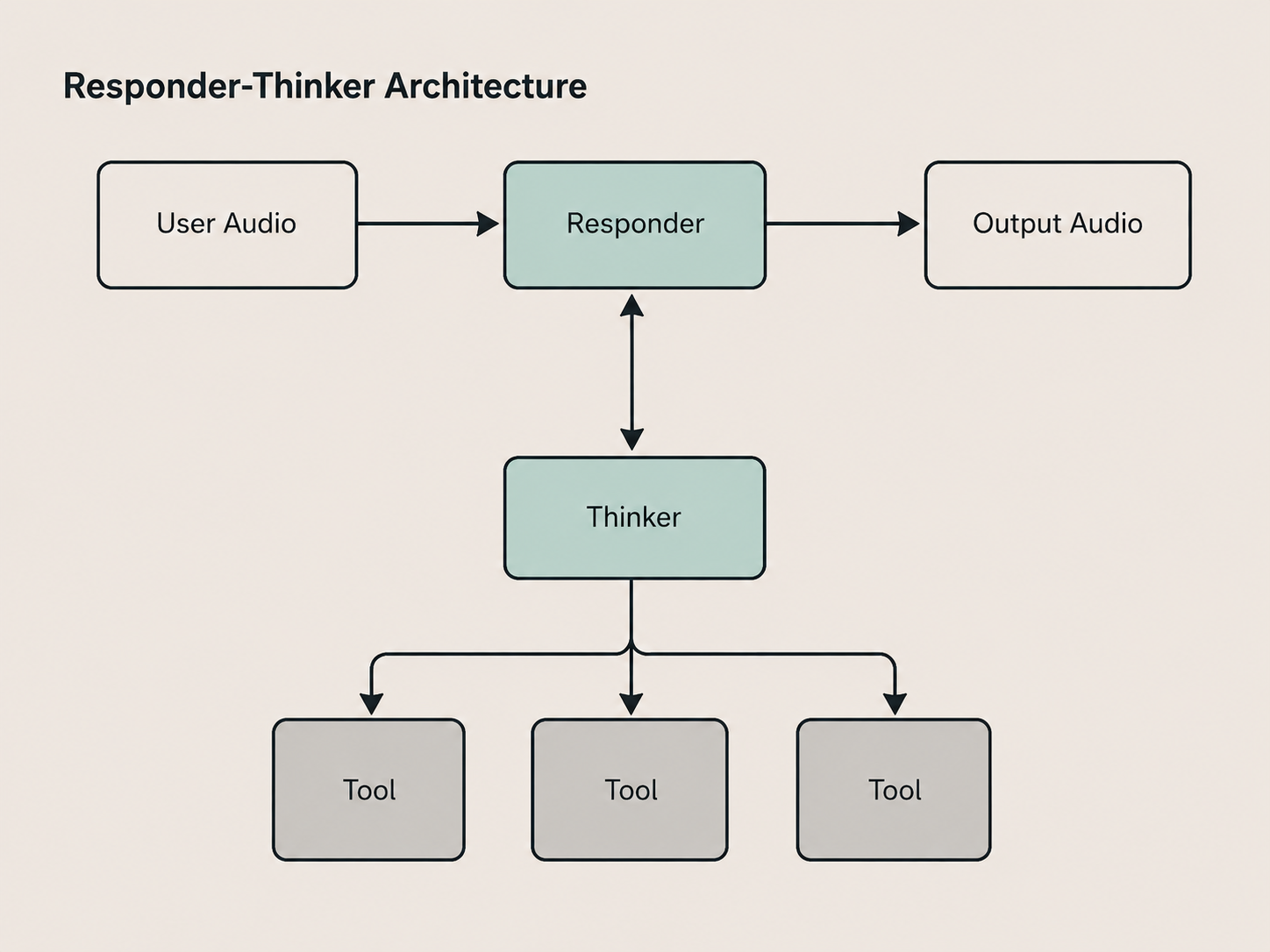
The thinker is a separate agent, powered by a reasoning-capable model. It operates out-of-band and handles tasks such as tool use, retrieval, and planning. The responder can call on it when needed and incorporate the results back into the conversation.
In some cases, the thinker may handle reasoning directly. In others, it may act as an orchestrator for a set of specialised agents. The key idea is that this work is done by a model more suited to reasoning tasks.
The payoff is simple: the responder can stay fast, conversational and focused, while the thinker handles work that needs more time, context or structure.
Future frontier model developments may render this approach unnecessary, but for now we’ve found this pattern to consistently outperform single agent approaches.
Event-driven Control
Realtime voice systems naturally produce a continuous stream of events.
Users begin speaking, pause, and interrupt. Transcripts update incrementally. Responses are generated and streamed. External results arrive. Conditions within the session evolve. All of these can be captured, streamed and stored as key events that created the specific current conversation state. Without them, we lose the ability to make granular and targeted interventions.
An event-driven approach provides a clear way to manage this. The system captures events as they occur, updates session state, and triggers the appropriate follow-up actions.
Lightweight handlers keep the realtime path responsive, while more involved tasks - such as updating state machines, logging metrics, removing sensitive information, updating databases and exiting a session - are triggered as asynchronous background tasks.
As features are added, the number of these background tasks can grow quickly. Even small product changes can introduce new event flows and dependencies. A well-structured architecture for this concurrency is important for keeping the system understandable and reliable as it evolves.
This event-driven approach also supports a critical product concern: shaping the conversation itself. A realtime audio system does more than generate replies; it manages pacing, handles silence and interruptions, and decides how and when a session should conclude. These behaviours are part of the product experience and benefit from explicit design.
As session state evolves based on turn count, elapsed time, or user behaviour, the system can inject targeted guidance to the responder. It might prompt the agent to help a user wrap up as they approach a session limit, or provide clarification if the interaction stalls. These interventions are lightweight but make the experience feel intentional and cohesive.
A well-designed system maintains a clear view of session state: who is speaking, how the conversation is progressing, and what conditions have been met. This state, updated continuously by the event stream, enables the right guidance at the right time.
Guardrails Have to Move at Realtime Pace
Guardrails are not optional in user-facing AI. They manage safety, compliance, misuse and reliability. In a turn-based system, there are obvious places to run them: after a user has spoken, or before a response is delivered.
Realtime voice removes most of those comfortable checkpoints. User input arrives continuously. Audio output may already be streaming. Finished transcripts often lag behind the sound. If the system waits for complete messages before checking them, the conversation stops feeling realtime.
Instead, guardrailing needs to operate alongside the conversation to preserve the lifelike interaction. One approach is to stream audio into a buffer while asynchronously evaluating transcript fragments as they become available, allowing safety checks to run at near-realtime pace without blocking the interaction.

When a guardrail triggers, the system can respond in-context by redirecting the conversation, adjusting behaviour, or ending the session where appropriate. This ensures guardrails work in realtime without degrading the user experience.
Realtime Evals are Hard
The hardest part of evaluating a realtime conversational system is that some of the most important qualities (timing, interruptions, flow, and tone) cannot be captured by transcript-only testing.
Standard eval pipelines feed realistic scenarios into the system, observe outputs, and score them. For text-based or chained-audio systems, this is straightforward: send text in, check text out. In realtime, the input is live audio, and the conversational dynamics that matter most exist in the temporal dimension: how the agent handles overlapping speech, how quickly it responds, how it recovers from an interruption.
Manual testing (speaking directly to the agent) captures these qualities but does not scale. Transcript-based automation scales but strips out the signal that differentiates a good realtime experience from a bad one.
No one method is enough. The practical answer is a stack:
- Agent-to-agent evaluations: a second realtime agent, instructed to inhabit a specific user persona, converses with the system under test. A third LLM-as-a-judge scores the interaction. This tests the full audio path, including timing and interruption handling, at volume.
- Non-functional metrics: time-to-first-audio and transcript sentiment analysis provide quantitative proxies for conversational quality.
- Manual qualitative review: still essential for catching issues that automated metrics miss, particularly around tone and naturalness.
No single method covers everything. Deploying realtime agents into production requires layering all three, and even then, the tooling for realtime audio evaluation remains immature compared to text-based AI.
Conclusion
Realtime voice changes the shape of the product. Users experience timing, interruption, silence and recovery as much as they experience the words.
That means the model is only part of the system. Production realtime voice needs a voice-native session layer, a clear split between speaking and reasoning, and event-driven control around the live session. Guardrails remain the latency bottleneck, but creative approaches can preserve much of the realtime experience.
The weakest part of the stack is still evaluation. There isn’t yet a settled way to test the qualities that make realtime voice feel good: timing, tone, interruption handling and conversational flow. Until that exists, teams building with the technology will need to combine automated tests, agent-to-agent runs and manual review.


